
This whitepaper documents our engineering practice in building PIF AI — a multi-tenant platform for cosmetic Product Information File (PIF) documentation. The project is three things at once: a product (serving Taiwan's cosmetic industry as the July 2026 PIF mandate takes full effect), a reference implementation (fully open-sourced under AGPL-3.0), and a case study (the entire project — code and this whitepaper — was built with Anthropic Claude Code).
The document spans 12 chapters + 4 appendices, ~80,000 Traditional Chinese characters and ~27,000 English words, with 15+ Mermaid diagrams. It is released under CC BY-NC 4.0 — free to download, cite, and translate. This post walks you through the five most important design decisions in ~10 minutes.
Why now
Taiwan's Cosmetic Hygiene and Safety Act was promulgated in 2018 and phased in from 2019. The final transition window ends on July 1, 2026. Starting that date, every cosmetic manufactured or imported in Taiwan must maintain a complete 16-item PIF. The TFDA (Taiwan FDA) may inspect at any time; non-compliance carries per-product fines of NT$10,000 to NT$1,000,000.
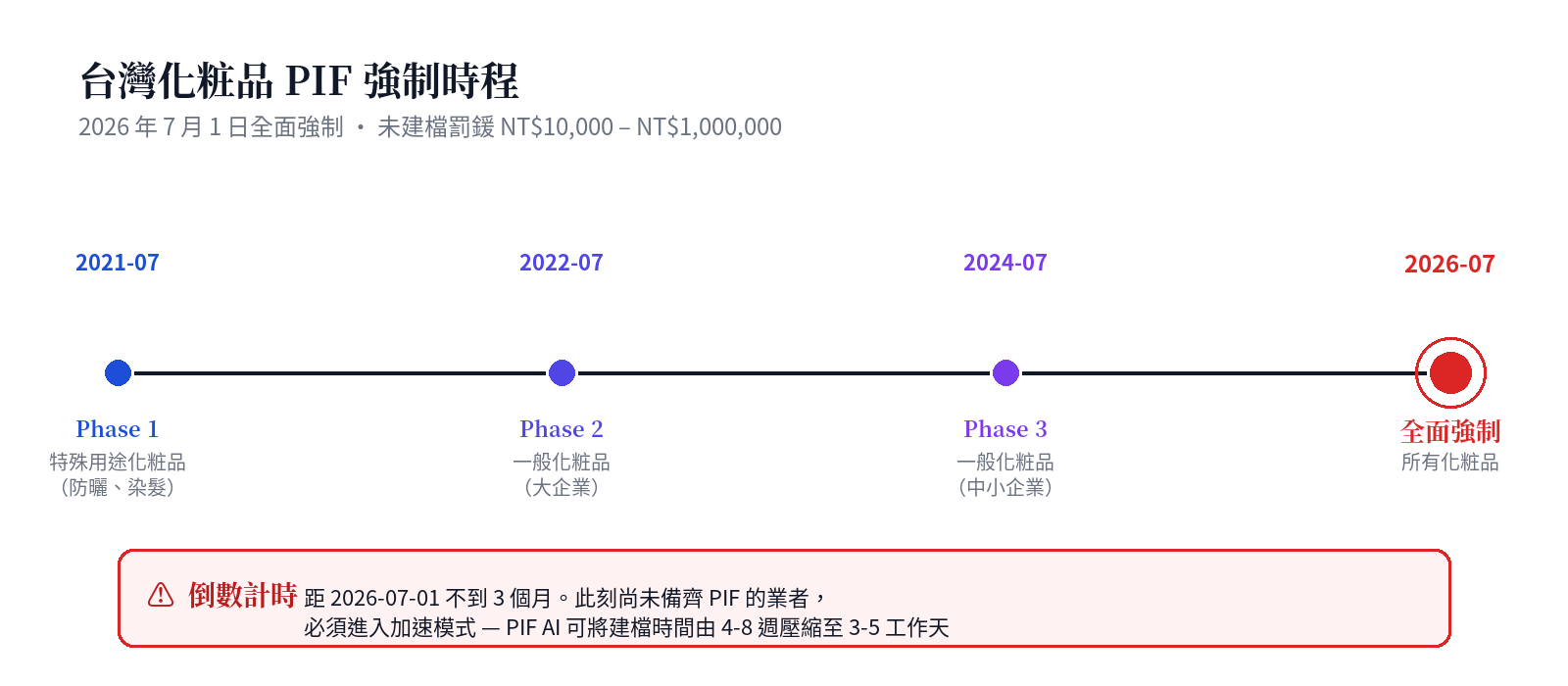
Traditional manual compilation takes 4–8 weeks per product — cross-database toxicology lookups, manual regulatory cross-checks against PDF annexes, and the mandatory sign-off by a qualified Safety Assessor (SA). For small and mid-size brands and contract manufacturers, the cost is crushing. PIF AI compresses this to 3–5 business days.
Proposition 1: Structured composition, not free-form generation
The default instinct for "AI document automation" is to have the LLM write each field. That's the wrong starting point. The 16 PIF items are largely a cross-document structured-information assembly problem: formulation sheets (Excel), GMP certificates (PDF), test reports, regulatory annexes (HTML/PDF), toxicology databases (JSON APIs). The bottleneck is data alignment and verification, not "writing ability."
This is exactly what LLM Tool Use excels at — letting the LLM act as a coordinator calling structured tools instead of stuffing all computation into token context. Whitepaper §7.2 shows the actual pipeline:
User uploads formulation.pdf → Claude Vision parses tables → each ingredient callsinci_normalize()→db_lookup_ingredient()checks internal records → on miss,pubchem_query(cas)→ concentration-sum validation (±2% tolerance) → returns{ingredients, confidence: 0.87}.
Every conclusion cites a source (PubChem CID, TFDA annex item, SCCS opinion number). The LLM does not fabricate numbers, making its output reviewable by the SA rather than requiring full rewrite.
Proposition 2: Scheme C+ — four layers of defense-in-depth isolation
Cosmetic formulations are trade secrets. Brand A's formulation must never leak to Brand B; and within a single brand owner, different products must also be isolated. Whitepaper §10 details our Scheme C+ — combining PIF's own backend with the central RAG service (rag.baiyuan.io) to provide four layers of defense-in-depth:
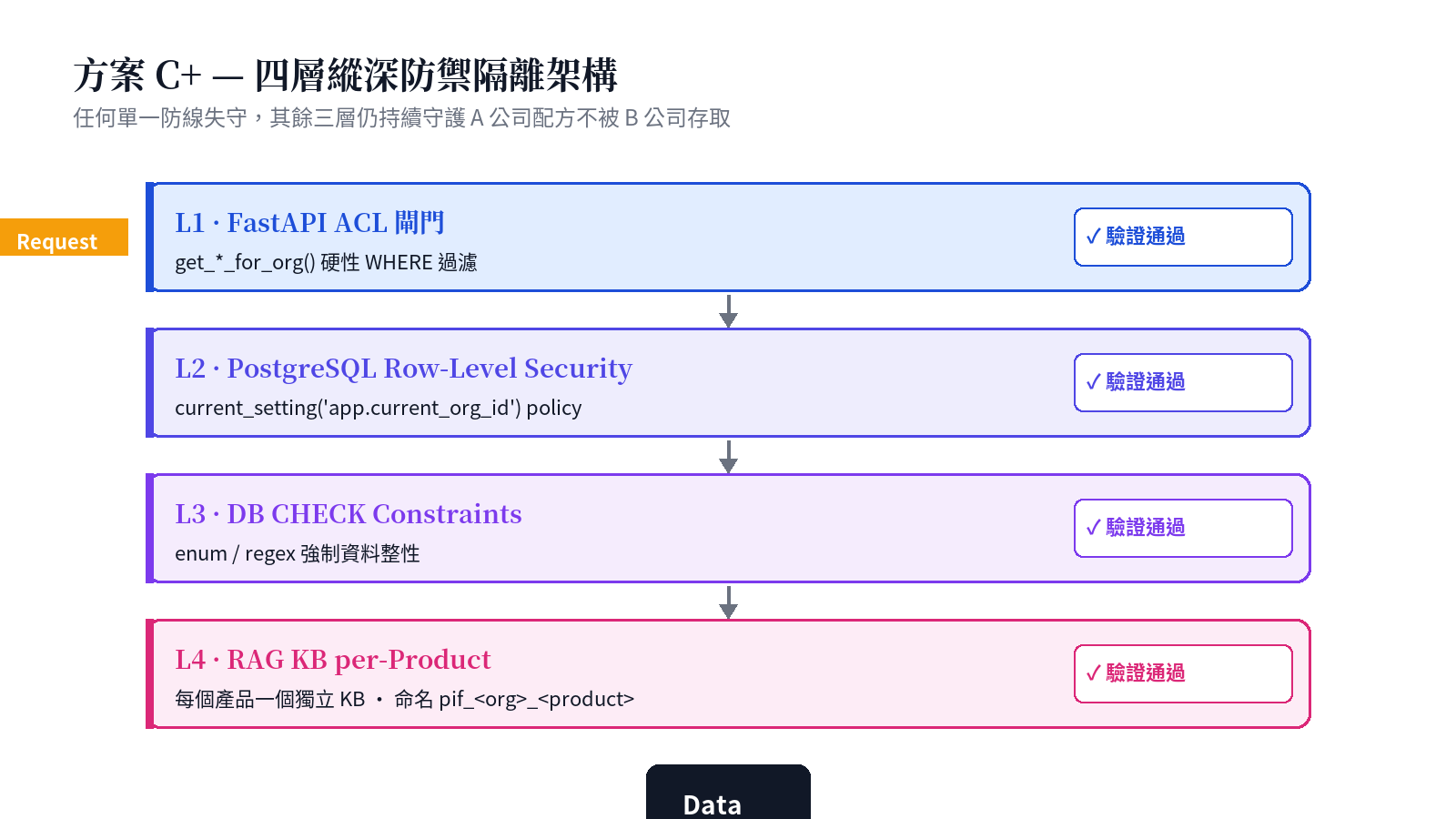
The key is L4: each PIF product has its own Knowledge Base (KB) in the central RAG, named pif_<org_id>_<product_id>, with metadata carrying pif_org_id and pif_product_id. PIF backend's ACL gate ensures the frontend never passes kb_id — it is always resolved server-side from products.rag_kb_id after SQL filtering by WHERE org_id = user.org_id.
This sidesteps the need to programmatically provision tenants in RAG v2 (which lacks a tenant-CRUD API) while achieving equivalent isolation strength via application + DB + RAG-layer defense.
Proposition 3: Central RAG's L1 Wiki + L2 vector dual-layer retrieval
PIF AI does not run its own vector database. Instead, it integrates the sibling project Baiyuan Central RAG v2 (rag.baiyuan.io), which uses an L1 LLM Wiki + L2 vector RAG dual-layer architecture — ideal for PIF's mix of "high-frequency canonical questions + occasional novel deep queries":
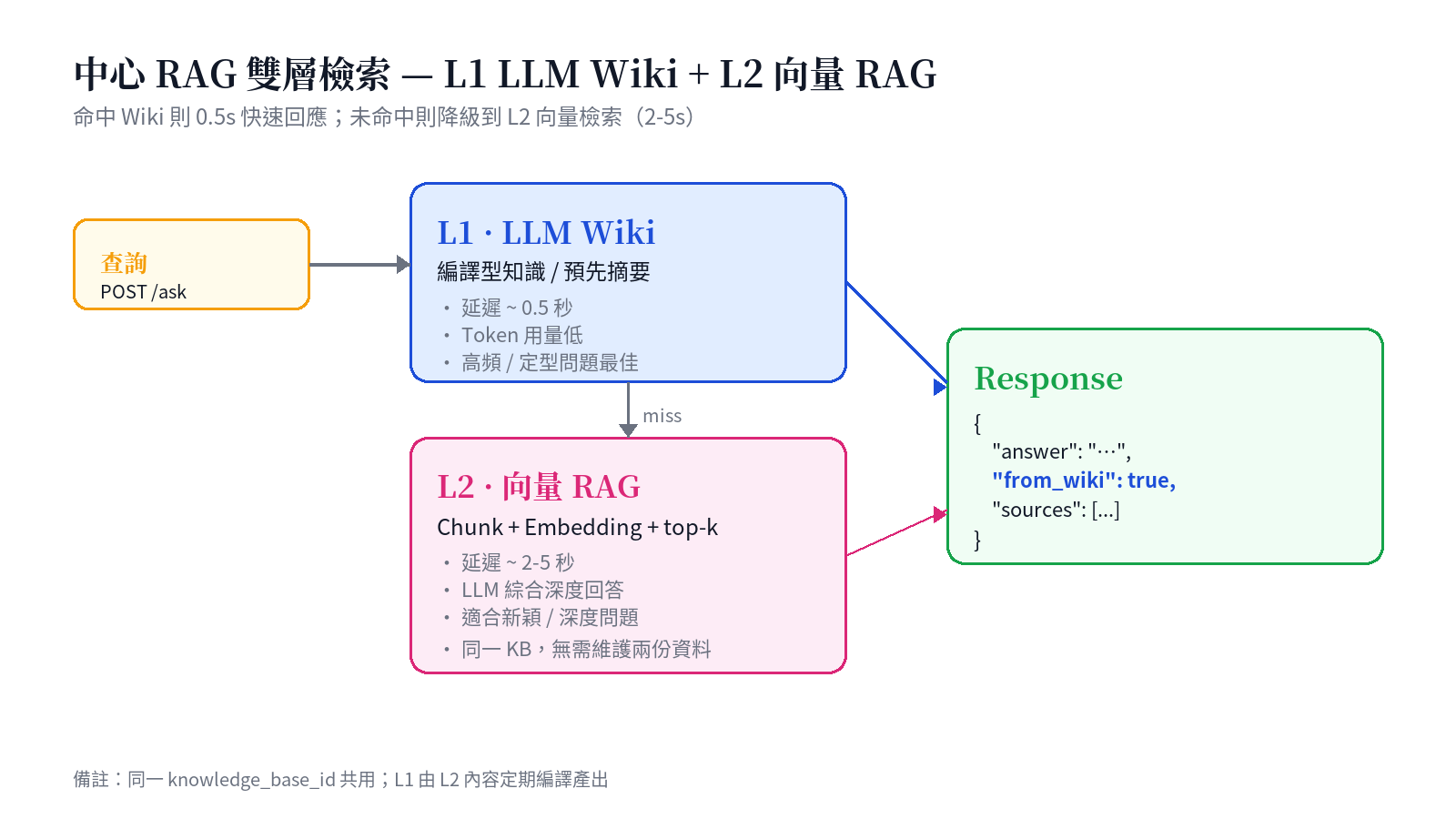
- L1 LLM Wiki (compiled) — pre-compiles KB content into structured entries; queries match title + summary. Hit → ~0.5s with minimal token spend. Best for "common regulatory definitions" and canonical questions.
- L2 Vector RAG (semantic) — fallback when L1 misses. Chunk → embedding → cosine similarity → top-k → LLM synthesis; ~2–5s latency but reaches details not yet compiled into Wiki.
Responses carry from_wiki: true|false; PIF UI displays a small indicator so users (or SAs) can see which tier answered.
Proposition 4: The "five-column mapping method" for 16 PIF items
This is the chapter (§3) with the highest transfer value for other teams. We systematically map every regulatory requirement to engineering work items using five columns:

The five columns: ① Regulation (text) → ② Data source (who provides? what format?) → ③ AI operation (parse / validate / compare / summarize) → ④ DB column (Table.Column or JSONB path) → ⑤ State-machine state (one of 6 states).
The value isn't PIF-specific — it's a reusable blueprint for any "regulation → engineering" translation. When extending to EU CPNP, US MoCRA, Japan's Yakukiho, or Korea's Cosmetics Act, the same five-column table applies.
Proposition 5: The entire project built with Claude Code
This is what we most want to share publicly: every part of PIF AI — frontend, backend, AI engine, RAG integration, deployment, 5-locale i18n, and this whitepaper's 80,000 Chinese characters — was built by the author collaborating with Anthropic Claude Code (Anthropic's official CLI agent). This is, as far as we know, the most complete and auditable open-source case study of "LLM-assisted engineering applied to commercial-scale SaaS."

All work is auditable in the commit trail, with every commit carrying a Co-Authored-By: Claude Opus 4.7 trailer. Two key cases:
- 5-locale i18n expansion (2026-04-19) — expanded from 2 to 5 locales (zh-TW / en / ja / ko / fr) with 423 keys of professional translation + dropdown component rewrite + TypeScript type-check + deployment, 45 minutes from requirement to live (commit
f33392e). - Central RAG integration (Scheme C+) — complete backend scaffold + 16 unit tests (
httpx.MockTransportidiom) produced without live credentials; one-flag enable when secrets arrived.
We also publicly document failures: cross-project credential reads blocked by the safety hook, attempts to auto-bypass test setup that required human correction. These are in §7.4.5.
Chapter quick index
- §1 Abstract & four design propositions + five-layer architecture
- §2 Regulatory background — Act Article 8, international comparison with EU CPR and US MoCRA
- §3 16 PIF items deep analysis + five-column mapping method
- §4 System architecture — five-layer unidirectional dependency + Bounded Context + observability
- §5 Frontend — Next.js 15 App Router + RSC + shadcn/ui + 5-locale i18n
- §6 Backend — FastAPI + SQLAlchemy async + dual Alembic / inline migration strategy
- §7 AI engine — Claude Tool Use + model routing + Claude Code practice
- §8 Database & multi-tenancy — PostgreSQL RLS +
current_settinginjection + formulation double encryption - §9 Toxicology pipeline — PubChem / TFDA / ECHA / OECD concurrent query + rule engine
- §10 Central RAG — Scheme C+ + L1/L2 dual-layer + fail-soft
- §11 Security — STRIDE + OWASP Top 10 + SA workflow TOTP second factor
- §12 Roadmap, deployment, open-source — Phase 1-3 + K8s migration + AGPL-3.0 rationale
- Appendix A–D — 50+ glossary entries, API endpoint list, references, changelog
Why you might want to read the full document
This whitepaper is not marketing copy; it is an engineering practice report: exposing why we designed it this way, which choices stumbled into which pits, and which patterns can be reused by other teams. If any of these fit, the full PDF is worth ~90 minutes:
- Cosmetic business owners (brands, OEMs, importers) facing the 2026-07 deadline without a clear path forward
- Regulatory consultants or SAs curious about how AI accelerates but does not replace professional judgment
- Architects looking to borrow multi-tenant isolation, fail-soft, and L1/L2 RAG patterns
- Teams considering Claude Code for complex SaaS wanting a specific, reproducible process, trade-offs, and failure cases
- Researchers studying LLM-assisted engineering's impact on the software lifecycle
License, source code, related resources
This whitepaper is released under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0):
- ✓ Free to download, read, cite, translate (please credit: Vincent Lin, PIF AI Whitepaper v0.1, Baiyuan Technology, 2026)
- ✓ Free to cite content and figures in papers, blogs, talks
- ✗ Not for commercial resale or packaging into paid products
- ✗ Attribution and source must not be removed
The underlying software (PIF AI platform) is licensed under AGPL-3.0, ensuring derivative-SaaS open-source obligations (rationale in §12.3). Related repos:
- 📄 baiyuan-tech/pif-whitepaper — whitepaper sources and PDF releases
- 🛠 baiyuan-tech/pif — platform source code (AGPL-3.0)
- 🌐 pif.baiyuan.io — live platform, open for trial
For commercial contexts (corporate training, internal reports) or customized versions, please reach us via the contact form.
Author: Vincent Lin (Head of Engineering, Baiyuan Technology)|Published 2026-04-19|Version v0.1
Baiyuan Technology is a company focused on enterprise AI infrastructure. Three product lines: outward-facing brand visibility via geo.baiyuan.io (GEO Platform); inward knowledge compounding via rag.baiyuan.io (RAG Wiki); and cosmetic-compliance documentation via pif.baiyuan.io (PIF AI).