
This whitepaper documents our 2024–2026 engineering practice in building the Baiyuan RAG Knowledge Platform — not a single product, but a shared infrastructure that concurrently powers three product lines: Baiyuan AI Customer Service SaaS, Baiyuan GEO Platform, and Baiyuan PIF AI.
The document spans 12 chapters + 4 appendices, ~45,000 Traditional Chinese characters, and ships with English + Japanese PDF editions under CC BY-NC 4.0. This post walks you through the five most important design decisions in ~10 minutes.
Why we wrote this
The whitepaper opens with "the dark forest of knowledge bases": enterprises drop PDFs into ChatGPT, and next day customers find the AI quoted wrong prices, wrong return policies, and leaked Company A's confidential docs to Company B. The issue isn't a poorly tuned prompt — it's infrastructure.
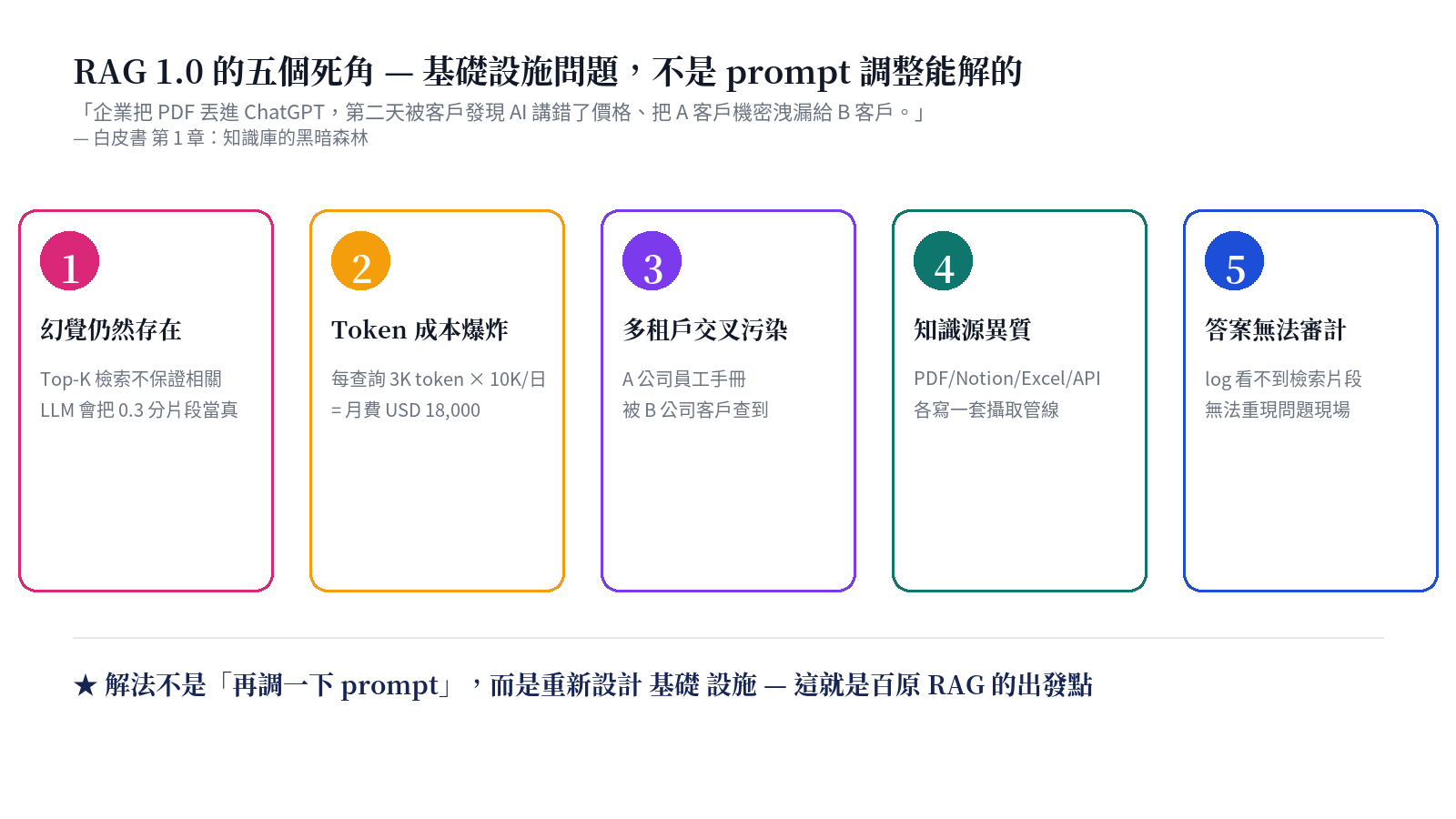
The five pitfalls are intertwined: reducing hallucination requires hybrid retrieval, which increases token cost; the root cause of tenant contamination is a shared embedding index without per-collection partitioning, but switching to partitioning changes fallback logic. The whitepaper argues: **treat them as one problem**, and an engineering solution becomes possible.
Proposition 1: Dual-layer retrieval — the core of 79% cost reduction
Chapters §3 + §4 + §5 form the book's core, answering one question: at SaaS scale, how do you make RAG both cheap and accurate? The answer: don't hit the LLM on every query.
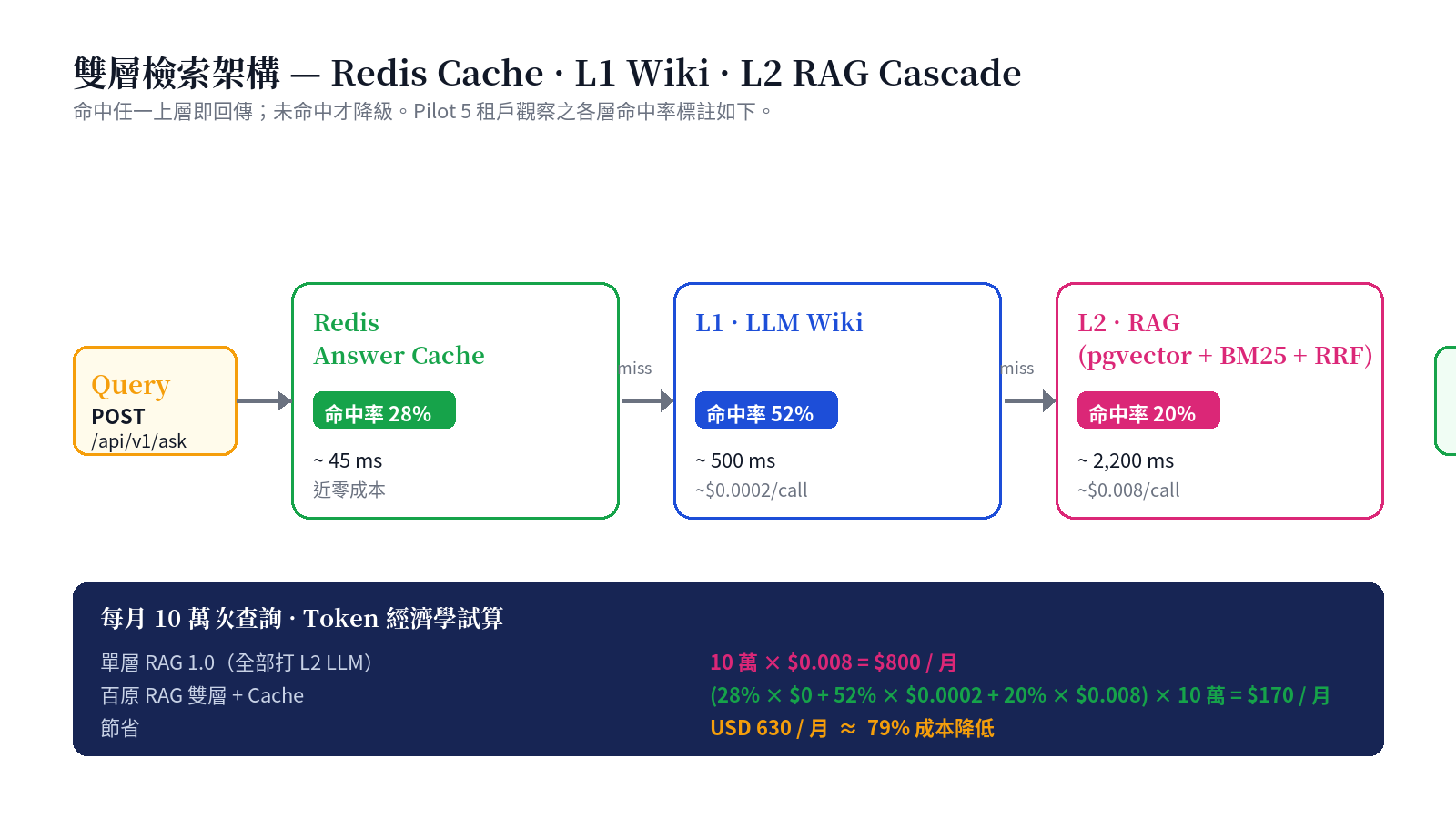
- Redis Answer Cache (~45 ms, near-zero cost): identical queries hit the cache directly; 28% of traffic stops here
- L1 · LLM Wiki (~500 ms, ~$0.0002/call): pre-compiled, DB-cached knowledge summaries answered via structured matching; 52% of traffic resolved at this layer
- L2 · RAG (~2,200 ms, ~$0.008/call): full pgvector + BM25 + RRF hybrid retrieval with LLM synthesis; only 20% of traffic reaches here
Monthly bill for 100K queries: single-layer RAG 1.0 is USD 800; dual-layer + cache is USD 170. 79% cost reduction, with 80% of queries answered in < 500 ms.
These aren't toy numbers — Whitepaper §11 discloses pilot-era hit-rate ranges (40–70% L1, 12–31% cache) across 12 tenants, with both flattering and unflattering cases documented.
Proposition 2: pgvector + BM25 + RRF — why not a dedicated vector DB
Most RAG stacks use Pinecone, Weaviate, or Qdrant. Baiyuan RAG stores vectors directly in PostgreSQL (via pgvector), combined with BM25 full-text search, fused via Reciprocal Rank Fusion (RRF). §4.2 gives the full rationale:
- Unified transaction boundary — vector writes and metadata writes commit together
- Lower ops cost — one less system to monitor / back up / upgrade
- Multi-tenancy alignment — PostgreSQL partitioning + Row-Level Security handles vectors and relational data uniformly
- Better hybrid recall — BM25 excels at rare keywords (product SKUs, regulatory clause numbers), vectors excel at semantics; RRF fuses both
- Low migration cost — if pgvector ever hits a ceiling, only the vector column's API changes; business logic stays
Measured: on "product SKU + Chinese description" hybrid queries, pure-vector recall@5 was 72%; adding BM25 + RRF raised it to 91%. This matters enormously in regulatory, medical, and technical-docs scenarios dense in rare keywords.
Proposition 3: Three-layer tenant isolation — the SaaS security floor
Company A's employee handbook must never be retrievable by Company B's customers. Whitepaper §6 describes three layers of defense-in-depth:
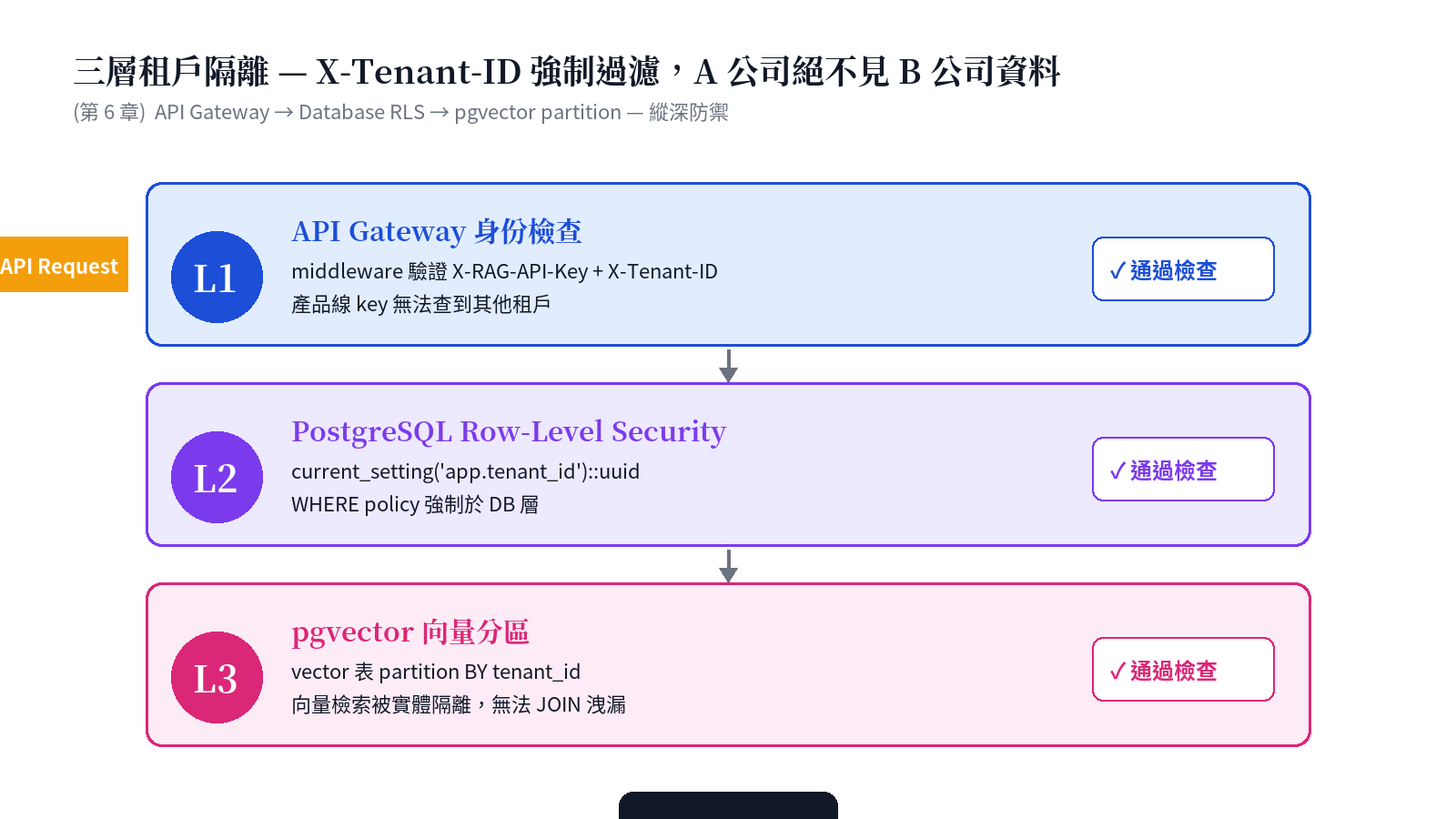
- L1 · API Gateway: middleware validates
X-RAG-API-Key+X-Tenant-IDdual headers. Even a leaked product-line key can't read other tenants. - L2 · PostgreSQL Row-Level Security: each session injects
app.tenant_id; WHERE policies enforced at DB layer. Application bugs cannot cross tenants. - L3 · pgvector partitioning: vector tables partitioned BY
tenant_id; physical isolation prevents plan-level joins across partitions.
If any single layer is bypassed, the other two still hold. This is defense-in-depth, not single-point-strongest — because single points always get bypassed eventually.
Proposition 4: One infrastructure, three product lines
This is the most transferable takeaway: don't build a separate RAG stack for each product line.
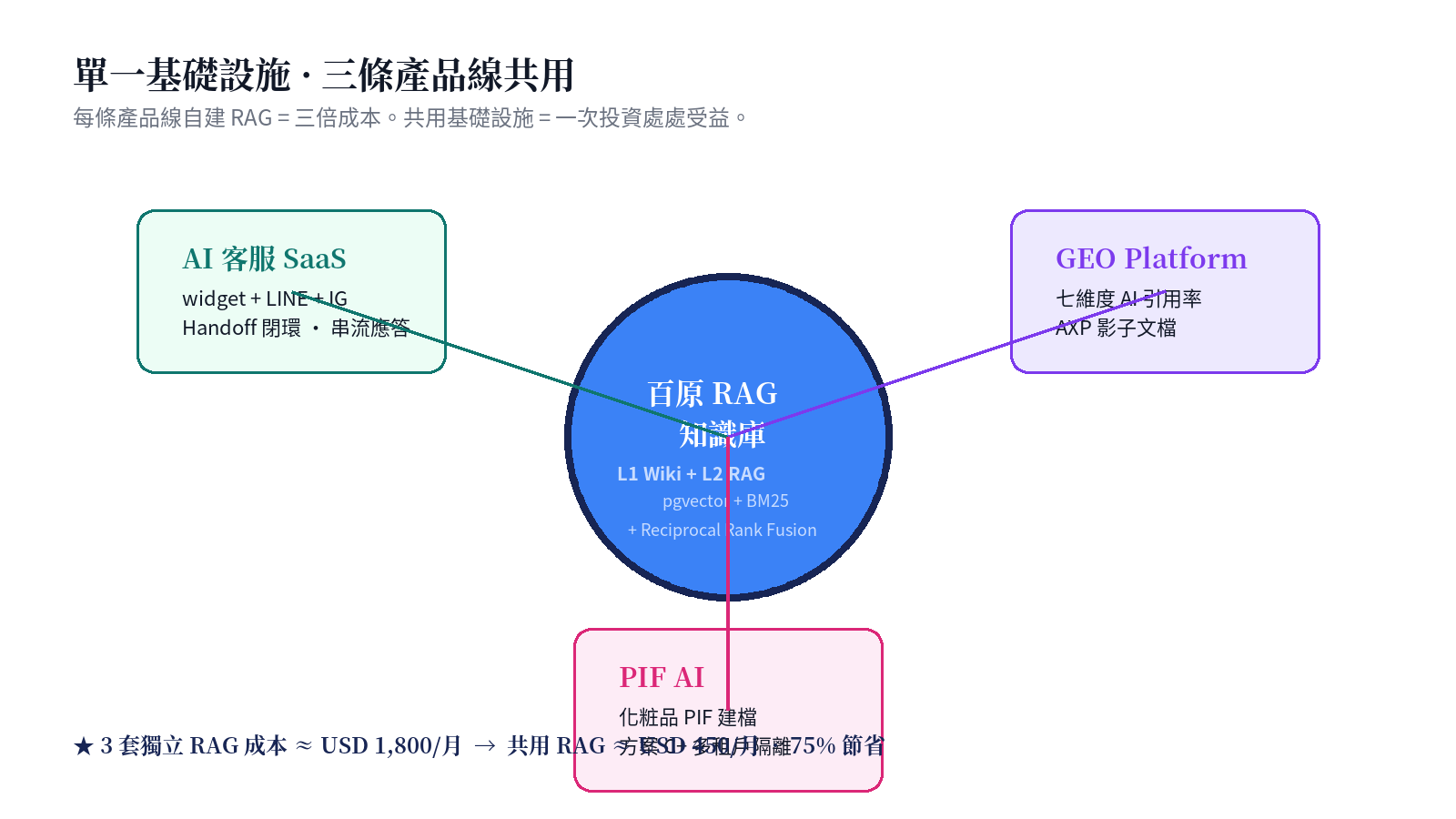
Product-line business logic differs enormously, but "feeding the LLM structured knowledge chunks + maintaining multi-tenant isolation" is identical across all three:
- AI Customer Service SaaS (§8, §11-A, §11-B) — live chat widget + LINE + Instagram; streaming answers + handoff-to-human loop
- GEO Platform (§9) — 7-dimension AI-citation-rate scoring; brand entities live in RAG; Schema.org three-layer entities mutually indexed with RAG KBs
- PIF AI (§10, §11-C) — cosmetic PIF 16-item documentation; each product gets its own KB (Scheme C+); toxicology data and regulatory clauses pre-compiled as L1 Wiki
Token economics doesn't only happen in the cache / L1 / L2 cascade — it also happens at the organizational level: "one infrastructure, three product lines." Three separate RAG stacks ≈ USD 1,800/month; shared RAG ≈ USD 450/month — 75% organizational-level savings.
Proposition 5: Real tenant observations — anonymized but unvarnished
Chapter §11 documents actual numbers from 12 pilot tenants, aggregated and de-identified:
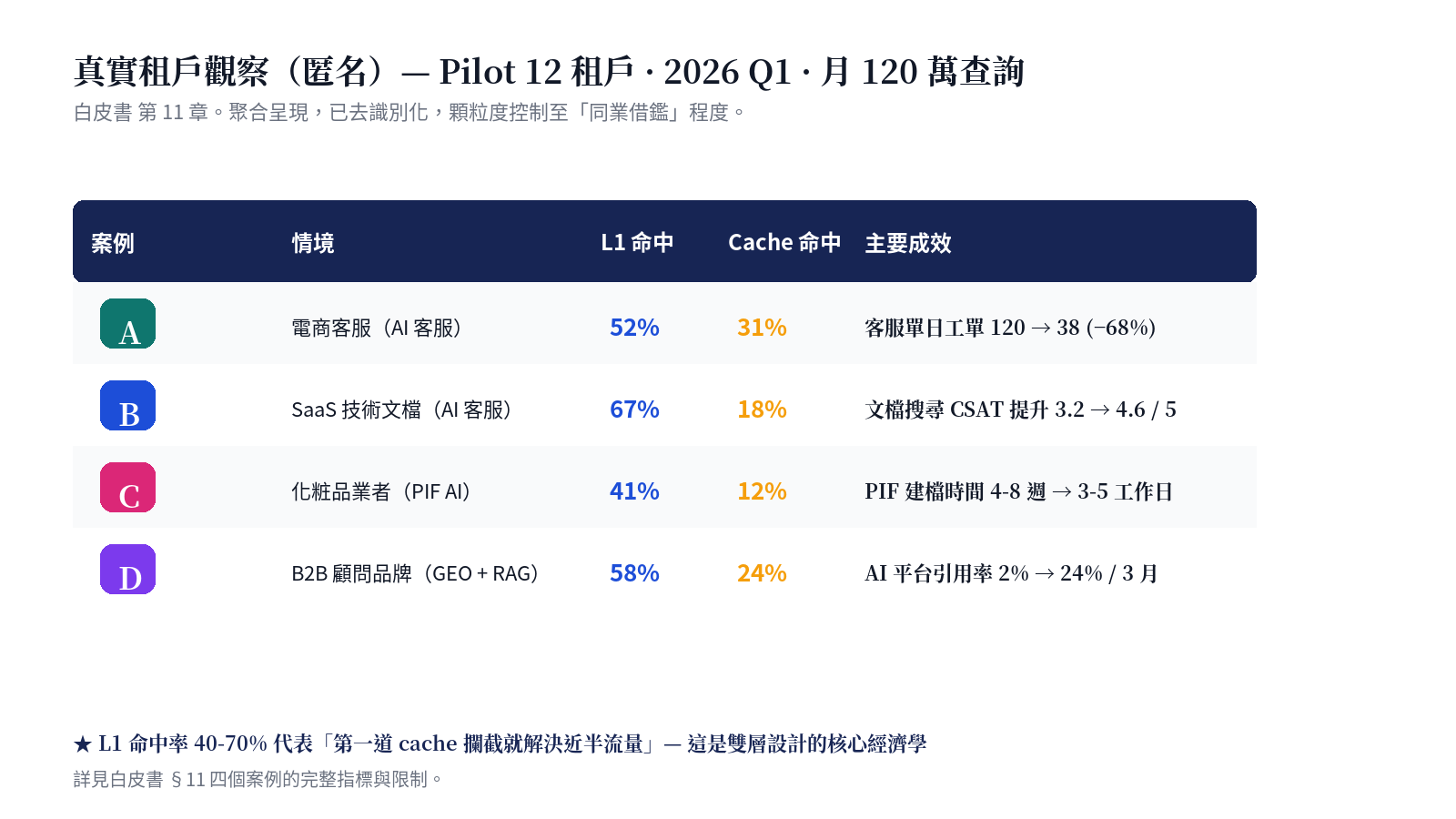
This chapter deliberately includes two "not so pretty" cases: a regulated-industry case with only 40% L1 hit rate (queries too specialized, compiler needed more work), and a full postmortem of a RAG answer error incident (§11.6.3 — how to trace via audit log + how we added a corrective rule to the Wiki compiler).
"Numbers don't lie — but they can be selectively silent. This chapter writes down both the flattering and unflattering." — opening of §11.
Chapter quick index
- §1 The Dark Forest — RAG 1.0's five structural pitfalls
- §2 System Overview — 9-stage request path, schema panorama, component breakdown
- §3 L1 Wiki — DB-cached knowledge compiler, refresh triggers, invalidation
- §4 L2 RAG — pgvector + BM25 + RRF implementation and tuning
- §5 Fallback + Token Economics — cost/latency models, multi-provider routing, graceful degradation
- §6 Three-Layer Tenant Isolation — API Gateway / RLS / vector partitioning in concert
- §7 Ingestion — unified pipeline for PDF / Notion / Excel / Web sources
- §8 Stream + Handoff — streaming answers, handoff-to-human loop, state machine
- §9 Integration with GEO Platform — shared brand entities, Schema.org interlinking
- §10 Integration with PIF AI — regulatory-vertical domain, per-product KBs, Scheme C+
- §11 Real Tenant Observations — 4 cases, both flattering and not
- §12 Limitations and Future Work — current pressure points, roadmap, assumptions we invite the community to challenge
- Appendix A–D — glossary, API endpoints, references, figure index
Why you might want to read the full document
This whitepaper is not a RAG tutorial nor a product pitch — it's a reproducible engineering practice report. If any of these apply, the full PDF is worth ~100 minutes:
- You are a CIO / CTO evaluating "build internal RAG" vs "buy SaaS"
- You are an architect wanting to understand the motivation and numbers behind L1 + L2 dual-layer design
- You are a backend engineer curious how pgvector + BM25 + RRF integrate in a single PostgreSQL instance
- You are a multi-product-line CTO considering shared AI infrastructure across product lines
- You are an AI / academic researcher interested in production RAG performance in SaaS contexts
License, source code, related resources
Released under CC BY-NC 4.0. Related repositories:
- 📄 baiyuan-tech/rag-whitepaper — this whitepaper's sources + trilingual PDF releases
- 📄 baiyuan-tech/geo-whitepaper — sibling: GEO Platform whitepaper
- 📄 baiyuan-tech/pif-whitepaper — sibling: PIF AI whitepaper
- 🌐 rag.baiyuan.io — RAG engine product site
- 🌐 geo.baiyuan.io · pif.baiyuan.io — sibling products
For commercial licensing, customized deployments, or internal training, reach us via the contact form.
Author: Vincent Lin (Head of Engineering, Baiyuan Technology)|Published 2026-04-20|Version v1.0-draft
Baiyuan Technology focuses on enterprise AI infrastructure. Three product lines: outward-facing brand visibility via geo.baiyuan.io (GEO Platform); inward knowledge compounding via rag.baiyuan.io (RAG Wiki); and cosmetic-compliance documentation via pif.baiyuan.io (PIF AI).