過去十年,你只需要看懂一隻爬蟲:Googlebot。
2026 年,你的網站每天被 16 隻爬蟲輪番拜訪。它們的身份、目的、抓取頻率、對品牌的意義 — 完全不一樣。
這篇文章從一張 Cloudflare 爬蟲面板的真實截圖出發,把這 16 隻爬蟲一隻一隻拆開來看:誰是誰、為什麼來、抓走多少、該不該開、怎麼設定最聰明。讀完之後,你會擁有一份可以直接貼到 robots.txt 的最優設定模板,並理解為什麼這樣設定。
這是 2026 年所有想做 GEO(Generative Engine Optimization)、想被 AI 答得準、想避開頻寬被吃光的網站經營者必修的一課。
一、為什麼一夜之間多了這麼多爬蟲?
過去網路上的爬蟲生態相對單純:搜尋引擎(Google、Bing、Yandex、Baidu)抓網頁建索引,再加上一些 SEO 工具(Ahrefs、SEMrush)。它們的邏輯一致 — 抓內容 → 建索引 → 排名 → 回流量。你只要確保 Googlebot 抓得到、爬得快,剩下的就是 SEO 的傳統工夫。
但 2023 年之後,世界變了。每一家做 AI 的公司,都開始派出自己的爬蟲到網路上抓內容。原因有三:
- 訓練資料的飢渴。GPT-4、Claude 3、Gemini、Llama 等大模型的訓練資料動輒數十兆 token,公開網頁是最大宗的來源。
- RAG 與即時引用的興起。AI 不只在訓練時看你的網站,當使用者問問題時,它還會即時抓你的最新頁面當答案來源並附引用。
- AI 助理的代理瀏覽。ChatGPT、Claude、Perplexity 提供「幫你上網查」的功能 — 使用者問什麼,AI 就以使用者身份去抓什麼。
結果是:你的 Cloudflare 面板上,過去只有 Googlebot 一隻爬蟲的位置,現在擠了 16 隻。每一隻都有不同的身份、用途、頻率、規則 — 用同一套 robots.txt 規則對待全部 16 隻,等於用同一個態度面對 16 個不同的客人。要做對 GEO,第一步就是學會分清楚它們。
二、30 天實測流量:誰才是真正的大胃王?
讓我們從數據開始。下面這張圖是百原科技兩個站 — www.baiyuan.io(品牌官網)與 geo.baiyuan.io(GEO 平台)— 在 Cloudflare AI Crawl Control 面板上的 30 天爬蟲流量合計排行。橫軸是傳輸量(KB),縱軸是爬蟲名稱,顏色依四種角色分類(後面會講四種角色的差異):

三個關鍵觀察:
第一,Googlebot 與 GPTBot 已經並駕齊驅。Googlebot 30 天抓走 4.39 MB、GPTBot 抓走 4.34 MB,差距僅有 50 KB。這是 2023 年完全不可能出現的局面。意思是:OpenAI 訓練爬蟲對你網站的興趣,已經跟 Google 搜尋一樣高。換句話說,如果你還在「只為 Googlebot 寫內容」,等於只服務了你網站訪客的一半。
第二,Meta 與字節跳動殺進前 5。Meta-ExternalAgent(負責訓練 Llama 與 Meta AI)抓走 2.71 MB,是第三大流量來源。Bytespider(字節跳動,負責訓練豆包 Doubao、TikTok AI、字節旗下所有 AI 產品)抓走 805 KB。這兩家在十年前根本不會出現在你的爬蟲日誌裡,今天合計流量超過 BingBot 7 倍。
第三,AI Search 與 AI Assistant 流量小但價值高。OAI-SearchBot、Applebot、PerplexityBot、ChatGPT-User、Perplexity-User 加起來總流量不到 800 KB,遠低於前面的訓練爬蟲。但它們每一次抓取,都對應到「使用者正在用 AI 問問題」 — 這些是離轉換最近的流量。封鎖它們等同於把已經舉手的潛在客戶推走。
看完總覽,先別急著結論。要真正知道每隻爬蟲該怎麼設定,得先理解它們其實分成四種完全不同的角色。
三、AI 時代的四種爬蟲角色
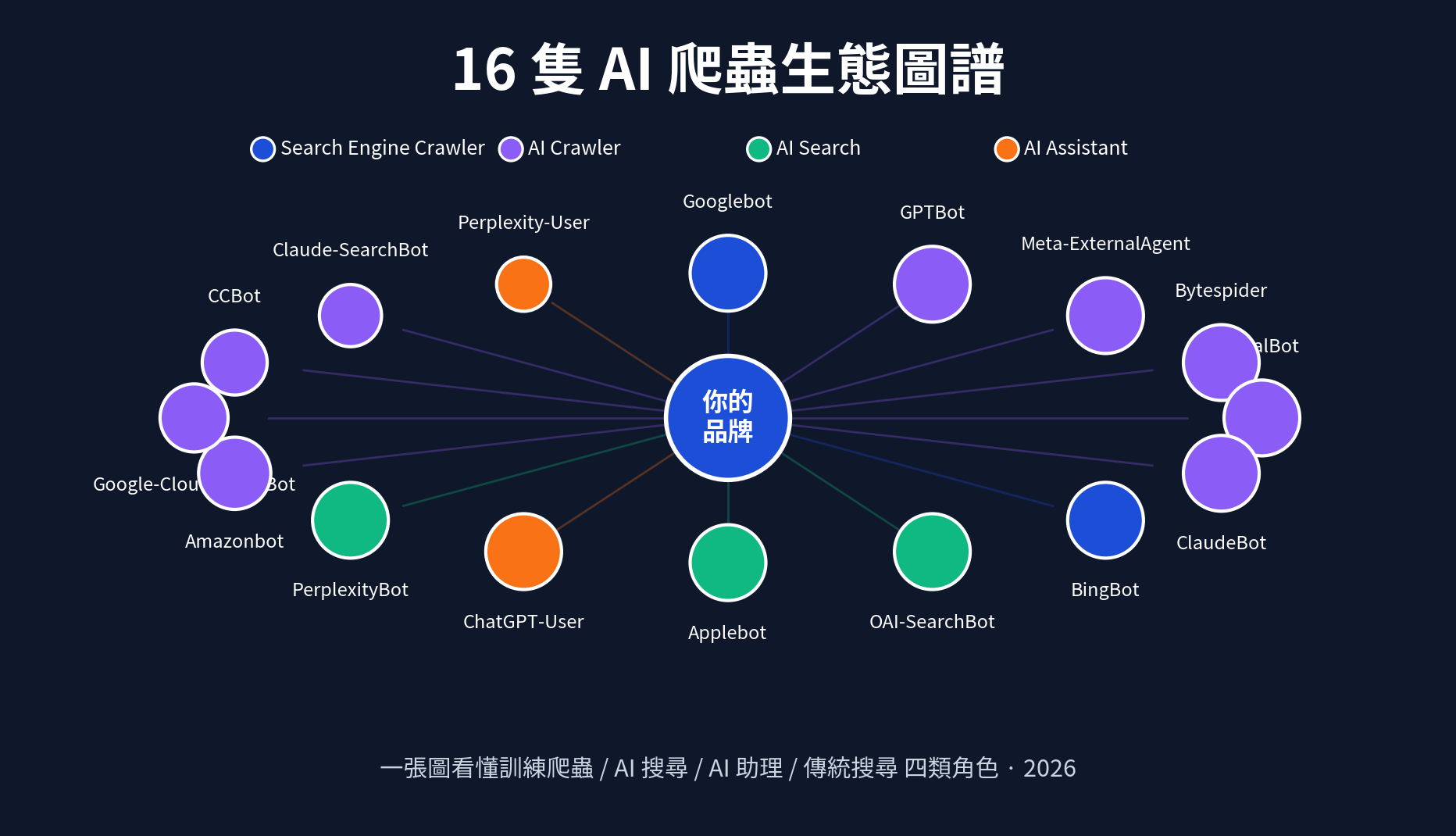
所有 AI 與搜尋爬蟲,可以乾淨地分成四類。每一類的用途、頻率、對品牌的價值、與該採取的策略都不一樣。Cloudflare 的爬蟲面板也是用這個分類法把每隻爬蟲標記出來:

四類的本質差異:
- 傳統搜尋(Search Engine Crawler):抓網頁 → 建索引 → 排名。代表:Googlebot、BingBot。必開,不開等於不存在。
- AI 訓練(AI Crawler):抓內容餵下一代大模型。代表:GPTBot、ClaudeBot、Meta-ExternalAgent、Bytespider、PetalBot、CCBot、Amazonbot、Google-CloudVertexBot、Claude-SearchBot。這是策略選擇的核心 — 開了就會被「學進去」,下次 AI 講你的時候比較可能對;關了你失去 AI 認知品牌的主動權,但保住了內容資產不被無償使用。
- AI 搜尋(AI Search):類似傳統搜尋,但回答時會即時抓你頁面當引用來源並附連結。代表:OAI-SearchBot(SearchGPT)、PerplexityBot、Applebot。強烈建議開 — 這是 GEO 的黃金通道,每一次引用都是直接曝光。
- AI 助理(AI Assistant):使用者在 ChatGPT、Perplexity 裡問你品牌相關的問題時,AI 即時去抓你的最新頁面。代表:ChatGPT-User、Perplexity-User。必開 — 每一次抓取都對應一個真實使用者正在了解你。
記住這個四象限。下一章逐隻分析時,每隻爬蟲都會回到這個分類來判斷。
四、16 隻爬蟲逐一深度解析
接下來進入本文核心 — 把每一隻爬蟲的身份、User-Agent、用途、頻率、本站 30 天數據、最優設置逐一拆開。我們按四類順序、再按本站流量從大到小排序。
1. Googlebot(Google · 傳統搜尋 · 4.39 MB / 340 允許 / 20 失敗)
身份:Google 搜尋的主力爬蟲,二十多年來幾乎所有網站經營者的第一名客人。
User-Agent:Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)(還有 Smartphone、Image、Video、News 等變體)。
用途:抓取網頁建立 Google 搜尋索引,順帶餵 Discover、Google AI Overview 等下游產品。
頻率特性:根據網站權重與更新頻率自動調節,活躍站每天可能來上百次。
本站數據:30 天 340 次允許、20 次失敗。失敗主要來自一些舊路徑被刪除返回 404,屬正常。
最優設置:永遠允許全站。如果你只能保留一隻爬蟲,就是它。在 robots.txt 不要對它加任何 Disallow,除非有特定後台路徑(如 /admin/)真的不該被索引。
2. BingBot(Microsoft · 傳統搜尋 · 489 KB / 41 允許 / 17 失敗)
身份:Microsoft Bing 的爬蟲,現在也餵 Copilot(Microsoft 的 AI 答題引擎,基於 OpenAI 模型 + Bing 索引)。
User-Agent:Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)
用途:Bing 搜尋索引 + Microsoft Copilot 答題引用來源。
頻率特性:流量遠小於 Googlebot 但比較禮貌,可以在 Bing Webmaster Tools 設定 crawl rate。
本站數據:30 天 41 次允許、17 次失敗(失敗率較高,可能是因為某些頁面回應慢被它放棄)。
最優設置:永遠允許全站。Bing 是 Copilot 的事實來源,封鎖 BingBot 等同於從 Microsoft 整個生態消失,包括 Office、Edge、Windows 內建搜尋。
3. GPTBot(OpenAI · AI 訓練 · 4.34 MB / 85 允許 / 25 失敗)
身份:OpenAI 的訓練資料爬蟲,2023 年 8 月推出。是目前流量最大的純訓練爬蟲。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.2; +https://openai.com/gptbot
用途:抓取網頁內容用於訓練 GPT 系列下一代模型(GPT-4.5、GPT-5、未來的 o4 等)。注意:GPTBot 抓到的內容會進入訓練資料,但不直接出現在 ChatGPT 的即時回答中(那是 OAI-SearchBot 的工作)。
頻率特性:相當積極,會深度爬取網站結構。
本站數據:30 天 85 次允許、25 次失敗(失敗率較高,OpenAI 的爬蟲對失敗回應比較不寬容)。
最優設置:建議允許全站。理由:你今天讓 GPTBot 學進你的品牌與服務細節,未來幾年使用者問 ChatGPT「哪家做 X 的好」時,你才有被推薦的機會。封鎖 GPTBot 是把自己排除在 ChatGPT 的「先驗認知」之外的最快方法。例外:如果你是付費內容、新聞媒體、版權密集型業務,可以選擇封鎖(後面講「全關派」會詳述)。
4. ChatGPT-User(OpenAI · AI 助理 · 170 KB / 11 允許 / 1 失敗)
身份:當使用者在 ChatGPT 裡啟用「Browse with web」或 ChatGPT 自己判斷需要查外網時,會以 ChatGPT-User 的身份代為瀏覽。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
用途:1:1 對應使用者請求,使用者問 A,ChatGPT 就以 ChatGPT-User 身份去抓 A 相關的頁面。
頻率特性:流量低(30 天 11 次),但每一次都對應一個真實使用者。
本站數據:30 天 11 次允許、1 次失敗。比例上非常乾淨。
最優設置:永遠允許全站,且不該限速。理由:每一次 ChatGPT-User 抓你的頁面,就是有一個使用者正在 ChatGPT 裡問你品牌相關的問題。封鎖等於把已經舉手的客戶推開。
5. OAI-SearchBot(OpenAI · AI 搜尋 · 195 KB / 6 允許 / 1 失敗)
身份:OpenAI 的搜尋索引爬蟲,為 SearchGPT、ChatGPT Search 建立可即時引用的搜尋索引。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-SearchBot/1.0; +https://openai.com/searchbot
用途:當使用者在 ChatGPT 開啟搜尋模式問問題時,OAI-SearchBot 預先建立的索引讓 ChatGPT 能即時回答並附引用連結。這是從 ChatGPT 反向引流的關鍵通道。
頻率特性:流量比 GPTBot 小很多,但每次抓取都有引用價值。
本站數據:30 天 6 次允許、1 次失敗。
最優設置:永遠允許全站。SearchGPT 是 OpenAI 對 Google 搜尋的直接挑戰,未來流量會越來越大。封鎖 OAI-SearchBot 等於關掉 ChatGPT 帶來的免費引用流量。
6. ClaudeBot(Anthropic · AI 訓練 · 630 KB / 87 允許 / 3 失敗)
身份:Anthropic 的訓練爬蟲,為 Claude 系列模型蒐集資料。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ClaudeBot/1.0; [email protected]
用途:抓取網頁訓練 Claude(包含 Claude Opus / Sonnet / Haiku 各代)。Anthropic 的爬蟲文件強調尊重 robots.txt、不會抓需要登入的內容、不會抓需要付費的內容。
頻率特性:相對禮貌,失敗率極低(30 天只有 3 次失敗)。
本站數據:30 天 87 次允許、3 次失敗。爬蟲品質相當高。
最優設置:建議允許全站。Claude 在 2026 年已是企業 AI 應用的第二大模型(僅次於 GPT),讓 ClaudeBot 學進你的品牌,等於同時打通 Claude 在 Claude.ai、API、Bedrock、Vertex AI 上的所有曝光通道。
7. Claude-SearchBot(Anthropic · AI 訓練 · 66 KB / 5 允許 / 4 失敗)
身份:Anthropic 在 2026 年推出的搜尋類爬蟲,搭配 Claude 的網路搜尋功能。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Claude-SearchBot/1.0; +https://www.anthropic.com/claude-searchbot
用途:當 Claude 啟用 web search 工具時,會以 Claude-SearchBot 抓取頁面當答案來源。本質上是 Anthropic 版的「OAI-SearchBot」。
頻率特性:流量小,因為 Claude 的網路搜尋功能還在推廣中。
本站數據:30 天 5 次允許、4 次失敗。失敗率偏高(44%),可能因為 Anthropic 新爬蟲還在優化。
最優設置:永遠允許全站。功能上等同 ChatGPT-User + OAI-SearchBot 的混合,是 Claude 給品牌的曝光通道。
8. Meta-ExternalAgent(Meta · AI 訓練 · 2.71 MB / 46 允許 / 5 失敗)
身份:Meta 的 AI 爬蟲,2024 年推出,為 Llama 系列模型與 Meta AI(Instagram、WhatsApp、Facebook 內建的 AI 助理)蒐集訓練資料。
User-Agent:meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/web-crawlers)
用途:訓練 Llama 4、Llama 5 等開源模型,以及 Meta 自家的閉源 AI 產品。
頻率特性:流量驚人 — 30 天 2.71 MB,是第三大流量來源。Meta 對訓練資料的飢渴度與 OpenAI 不相上下。
本站數據:30 天 46 次允許、5 次失敗。
最優設置:建議允許全站。Llama 是目前最大宗的開源模型,被全球無數企業二次微調使用 — 進入 Llama 訓練集等於進入幾百個下游應用的「先驗知識」。例外:如果你對 Meta 的版權與商業使用條款有疑慮(Meta 的條款歷史上對內容創作者較不友善),可以考慮限速或封鎖。
9. Bytespider(ByteDance · AI 訓練 · 805 KB / 26 允許 / 2 失敗)
身份:字節跳動的爬蟲,為豆包(Doubao)、TikTok、抖音內 AI 功能、Coze 等字節旗下所有 AI 產品蒐集訓練資料。
User-Agent:Mozilla/5.0 (compatible; Bytespider; [email protected])
用途:訓練字節旗下中英雙語大模型,覆蓋豆包 PC/手機版、TikTok 智能客服、剪映 AI 等。
頻率特性:早期有過很積極(甚至被認為太積極)的歷史,2025 年後較收斂,但仍是亞洲爬蟲中流量最大的一隻。
本站數據:30 天 26 次允許、2 次失敗。
最優設置:建議允許,可選擇性限速。如果你的目標市場包含中文圈(特別是中國大陸、東南亞華人市場),讓 Bytespider 抓很重要 — 豆包與 TikTok 是中文 AI 流量第一大宗。但如果你完全不做中國市場,可以單獨對 Bytespider 加 Crawl-delay。
10. PetalBot(Huawei · AI 訓練 · 648 KB / 48 允許 / 0 失敗)
身份:華為 Petal Search 與華為小藝 AI 助理的爬蟲。
User-Agent:Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot)
用途:為華為手機、平板、智慧屏內建的 Petal Search、小藝 AI 助理建立索引。
頻率特性:禮貌爬蟲(30 天 48 次抓取、0 次失敗,幾乎完美)。
本站數據:30 天 48 次允許、0 次失敗。
最優設置:允許全站。華為全球終端裝置數量龐大(特別在中國、中東、非洲、東南亞),Petal 是這些區域用戶的預設搜尋來源。封鎖等於放棄這些市場的曝光。
11. Applebot(Apple · AI 搜尋 · 194 KB / 25 允許 / 1 失敗)
身份:Apple 的爬蟲,為 Siri、Spotlight、Safari 智能建議、Apple Intelligence、未來的 Apple 搜尋產品建立索引。
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
用途:除了搜尋索引,從 iOS 18.1 起 Applebot 抓的內容也會用於 Apple Intelligence(Apple 的端側 + 雲端 AI 體系)。
頻率特性:保守、禮貌、高品質。
本站數據:30 天 25 次允許、1 次失敗。
最優設置:永遠允許全站。Apple 全球裝置數十億,Siri 與 Spotlight 是這些裝置上的入口。
12. PerplexityBot(Perplexity · AI 搜尋 · 109 KB / 7 允許 / 1 失敗)
身份:Perplexity AI 的搜尋索引爬蟲。Perplexity 是 2024–2026 年最快成長的 AI 答題搜尋引擎。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot
用途:建立索引讓 Perplexity 在使用者提問時即時引用,並在回答中附上來源連結。
頻率特性:流量小但每次都對應引用。
本站數據:30 天 7 次允許、1 次失敗。
最優設置:永遠允許全站。Perplexity 是少數真的會在回答中清楚標示來源連結的 AI 平台,引用價值極高。它在科技、商業、研究類查詢上的市占率已經接近 Google。
13. Perplexity-User(Perplexity · AI 助理 · 49 KB / 4 允許 / 5 失敗)
身份:當 Perplexity 使用者問問題、Perplexity 需要即時抓特定網頁時的代理身份。
User-Agent:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user
用途:1:1 對應使用者請求(Perplexity 版的 ChatGPT-User)。
頻率特性:流量很小但失敗率偏高(30 天 4 次允許、5 次失敗,失敗率 55%)。失敗率高的原因通常是頁面 timeout 或被 WAF 攔截。
本站數據:30 天 4 次允許、5 次失敗。
最優設置:永遠允許,且需排除在 WAF 嚴格規則之外。如果你的網站對 Perplexity-User 失敗率超過 30%,建議檢查:是否被 Cloudflare 的 Bot Fight Mode 誤判?頁面回應時間是否超過 Perplexity 的 timeout?
14. Google-CloudVertexBot(Google · AI 訓練 · 79 KB / 5 允許 / 4 失敗)
身份:Google Cloud Vertex AI(Google 的企業級 AI 平台)的爬蟲,由企業客戶在 Vertex AI 上建立 RAG 應用時觸發。
User-Agent:Mozilla/5.0 (compatible; Google-CloudVertexBot/1.0; +http://www.google.com/bot.html)
用途:當企業在 Google Cloud 上用 Vertex AI 建立 RAG 知識庫、要把你的網站當作資料來源時,Vertex AI 會派這隻爬蟲去抓。
頻率特性:完全由企業客戶觸發,流量極低且隨機。
本站數據:30 天 5 次允許、4 次失敗。失敗率偏高,可能是 Vertex AI 對失敗回應比較不寬容。
最優設置:允許全站。流量小到不需要擔心,但封鎖會讓某個 Google Cloud 企業客戶的 RAG 系統少了你這個來源 — 可能就此把你排除在他們的 AI 應用之外。
15. Amazonbot(Amazon · AI 訓練 · 89 KB / 8 允許 / 0 失敗)
身份:Amazon 的爬蟲,為 Alexa Q&A、Amazon Bedrock 上的模型應用、Amazon 自家 AI 產品蒐集內容。
User-Agent:Mozilla/5.0 (compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot)
用途:除了 Alexa,Amazon 的 Rufus(Amazon 的購物 AI 助理)、AWS Bedrock 等 AI 產品也會用到這些資料。
頻率特性:禮貌且低頻(30 天 8 次抓取、0 次失敗)。
本站數據:30 天 8 次允許、0 次失敗。
最優設置:允許全站。Amazonbot 是少數做事很乾淨的爬蟲,封鎖它的成本(失去 Alexa / Rufus / Bedrock 曝光)遠大於開放的成本。
16. CCBot(Common Crawl · AI 訓練 · 72 KB / 5 允許 / 2 失敗)
身份:Common Crawl 基金會的爬蟲,每個月抓一次全網建立公開資料集。
User-Agent:CCBot/2.0 (https://commoncrawl.org/faq/)
用途:Common Crawl 是所有大模型的訓練資料基石。GPT、Claude、Gemini、Llama、Mistral、Qwen — 沒有任何一個主流大模型不用 Common Crawl 的資料集(C4 / RedPajama / The Pile 等子集都源於它)。
頻率特性:每月一次掃描,每次拿走的不多但是分散性極廣。
本站數據:30 天 5 次允許、2 次失敗。
最優設置:策略性決定。允許 CCBot 等於允許未來所有大模型都看得到你的內容(包括你不知道的、還沒推出的模型)。封鎖 CCBot 是最高槓桿的訓練資料隔離手段 — 但要記得,這也表示你永遠不會出現在那些用 CC 資料訓練的模型裡。建議:除非你是版權密集型產業(新聞、出版、學術),否則允許。
看完 16 隻,你應該已經注意到一個關鍵事實:「該允許」的爬蟲比「該封鎖」的多很多。這跟很多人直覺的「AI 爬蟲都來偷我內容」相反 — 因為其中大部分爬蟲,把你的內容拿走之後是要把你展示給使用者,而不是把你「藏起來」。
但這不表示無腦全開最好。下面進入策略層。
五、三種設定哲學 — 沒有對錯,只有適配
面對這 16 隻爬蟲,業界存在三種主流的設定哲學。三種都各有合理性,差別只在於你的內容是什麼、你的商業模式是什麼、你怎麼算 ROI:

全開派(Open House):允許所有爬蟲、不加任何限制。適合剛起步的品牌、新創公司、內容行銷導向的 B2B 服務商。核心邏輯:寧可被學「壞」也不要不存在 — 此時你最大的風險不是內容被 AI 拿走,是 AI 根本不知道你是誰。代價:頻寬成本上升、頂級內容(白皮書、研究報告)會被未經授權使用。
篩選派(Selective):百原科技推薦給多數中小企業的策略。原則:
- AI Search 與 AI Assistant(OAI-SearchBot、PerplexityBot、Applebot、ChatGPT-User、Perplexity-User、Claude-SearchBot)→ 全部允許、且優先排除在 WAF 嚴格規則之外。
- 傳統搜尋(Googlebot、BingBot)→ 全部允許。
- AI Crawler 中的「主流好公民」(GPTBot、ClaudeBot、Applebot、Amazonbot、PetalBot)→ 允許。
- AI Crawler 中的「重流量者」(Meta-ExternalAgent、Bytespider、CCBot)→ 允許但限速或限路徑。例如不讓它們抓 PDF、影片、archive 區。
全關派(Defensive):封鎖所有 AI Crawler(保留傳統搜尋與 AI Search + AI Assistant)。適合:付費內容業者、新聞媒體、版權密集型企業(出版社、學術期刊、智財權服務)。核心邏輯:守住內容資產 > GEO 曝光。代價:完全退出 AI 答案戰場、未來幾年將被 AI 認知為「不存在的品牌」。
百原科技的觀察:絕大多數台灣中小企業適合篩選派。你的內容不是付費資產(不需要全關),但你的頻寬與伺服器有成本(不需要全開)。下一節給你可以直接貼上的 robots.txt 模板。
六、百原科技推薦的最優 robots.txt 模板
把上面的策略翻譯成可貼上的 robots.txt。下面這份是百原科技推薦給「篩選派」中小企業的版本,已實際部署於 www.baiyuan.io:
# =====================================================
# robots.txt — 百原科技 GEO 篩選派模板(2026 版)
# 策略:開 AI Search / Assistant、開主流訓練爬蟲、限速重量級
# =====================================================
# --- 傳統搜尋:永遠全開 ---
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# --- AI Search:強烈建議全開(GEO 黃金通道)---
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Applebot
Allow: /
# --- AI Assistant:必開(每一次都是真實用戶)---
User-agent: ChatGPT-User
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
# --- AI Crawler 主流:允許全站 ---
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PetalBot
Allow: /
User-agent: Amazonbot
Allow: /
User-agent: Google-CloudVertexBot
Allow: /
# --- AI Crawler 重流量:允許但限速、排除大型靜態資產 ---
User-agent: Meta-ExternalAgent
Crawl-delay: 10
Disallow: /downloads/
Disallow: /*.pdf$
Disallow: /*.zip$
User-agent: Bytespider
Crawl-delay: 10
Disallow: /downloads/
Disallow: /*.pdf$
Disallow: /*.zip$
User-agent: CCBot
Crawl-delay: 15
Disallow: /downloads/
# --- 通用 fallback:未列出的爬蟲一律允許但保守 ---
User-agent: *
Allow: /
Disallow: /admin/
Disallow: /api/
Disallow: /draft/
Crawl-delay: 5
# --- sitemap 指引 ---
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap-index.xml
重點註釋:
- 明確列出每隻爬蟲,而不是只寫一條
User-agent: *。明確列名讓爬蟲不會走 fallback、規則精準對應。 Crawl-delay只對重量級爬蟲使用。Googlebot、GPTBot 本身有更聰明的調節邏輯,加Crawl-delay反而會降低你的抓取頻率(負面)。- 排除大型靜態資產(PDF、ZIP、影片)對訓練爬蟲意義不大,但會消耗大量頻寬。
- 保留
/admin/、/api/的封鎖。這些路徑不該出現在任何 AI 答案裡。 - 放在
https://your-domain/robots.txt的根路徑。子目錄無效。
七、5 個最常見的 robots.txt 設定錯誤與排查方法
有了模板還不夠。我們在百原科技做 GEO 健檢的這兩年,看過數百個品牌的 robots.txt 與 WAF 設定,總結出 5 個最常見、也最致命的設定錯誤。每一個都會讓你的品牌在 AI 答案中無聲消失,而你完全不知道。
錯誤 1:用一條 User-agent: * 全部封鎖,以為「比較安全」
最常見、也最致命的錯誤。我們看過某家本地老牌服飾品牌,因為早期擔心「AI 偷內容」,在 robots.txt 寫了:
User-agent: *
Disallow: /結果是:所有爬蟲都被擋了,包括 Googlebot。三個月後品牌官網從 Google 搜尋結果消失,新客戶詢價量歸零,業主才驚覺出問題。排查方法:到 Google Search Console 的「網址檢查」工具,輸入官網首頁,看是否被 robots.txt 阻擋。Bing Webmaster Tools 也有同樣功能。如果發現被擋,立刻把上面那行刪掉。
錯誤 2:對 AI Search 爬蟲套用 Crawl-delay 拖慢回應
有些網管出於「省頻寬」的好意,對所有 AI 相關爬蟲統一加上 Crawl-delay: 30。問題是 — AI Search 與 AI Assistant 爬蟲(OAI-SearchBot、ChatGPT-User、Perplexity-User、Claude-SearchBot)每次抓取都對應一個真實使用者正在等答案。對它們加 Crawl-delay,等於告訴 AI「請告訴你的使用者多等 30 秒」 — 結果就是 AI 直接跳過你、改引用別家。
排查方法:定期檢查爬蟲面板上 AI Assistant 類爬蟲的失敗率。如果 ChatGPT-User 或 Perplexity-User 的失敗率 > 30%,幾乎可以肯定是 Crawl-delay 或 WAF 規則造成的。
錯誤 3:把 AI Search 爬蟲跟「壞爬蟲」混為一談、套用 Bot Fight Mode
Cloudflare 的 Bot Fight Mode、Super Bot Fight Mode 是強力工具,但預設規則對 AI 爬蟲不友善。它的演算法傾向把「沒有瀏覽器指紋、純機器人」的請求一律加挑戰(CAPTCHA、JavaScript challenge)。AI 爬蟲沒有真實瀏覽器、無法解 JS challenge,結果就是 100% 失敗。
排查方法:在 Cloudflare 主控台「Security → Bots」找到「Verified bots」白名單,確保 OAI-SearchBot、PerplexityBot、ClaudeBot 等被驗證爬蟲都在白名單。另外,到「Security → AI Crawl Control」面板,個別爬蟲設「允許 Allow」而非「挑戰 Challenge」。
錯誤 4:用 Cloudflare 的「Country Block」連帶擋掉 AI 爬蟲源頭 IP
有些品牌做地理封鎖(例如只服務台灣,封鎖中國、俄羅斯 IP),結果意外把來自美國 AWS、Google Cloud、Azure 機房的 AI 爬蟲一併擋了 — 因為 OpenAI、Anthropic、Perplexity 的爬蟲都跑在這幾家雲上。常見症狀:GPTBot、ClaudeBot 的允許次數突然歸零。
排查方法:檢查 Cloudflare「Security → WAF → Custom Rules」是否有 country-based 封鎖規則。如果有,加一條例外:(cf.client.bot) and (cf.verified_bot_category in {"AI Crawler" "AI Search" "AI Assistant" "Search Engine Crawler"}) → Skip。這條規則的意思是「已驗證的爬蟲跳過地理封鎖」。
錯誤 5:用 noindex meta 卻沒在 robots.txt 對應放行
很多人以為在 HTML 加 <meta name="robots" content="noindex"> 就能讓爬蟲不索引但仍能讀取頁面,這樣 AI 答題時還能引用、又不會出現在 Google 搜尋結果。但這有個關鍵前提:爬蟲要先能讀到那個頁面,才會看到 noindex 標籤。如果你的 robots.txt 把該路徑 Disallow,爬蟲根本不會去抓,自然也不會看到 noindex;於是該頁面仍然會以 URL 形式出現在 Google「無描述索引」中,反而是最差結果。
排查方法:noindex 必須搭配 robots.txt 的 Allow(或不寫 Disallow),讓爬蟲能進入頁面讀到 noindex 標籤。如果想要完全不被任何爬蟲看見,正確做法是用伺服器層的密碼保護或 IP 白名單,而不是 robots.txt + noindex 混搭。
這 5 個錯誤的共同點:都是「過度防禦」造成的傷害。AI 爬蟲生態真正的風險,不是被學壞 — 是被自己的設定意外封鎖、結果完全消失在 AI 答案裡。
八、進階:Cloudflare AI Crawl Control 與 llms.txt
robots.txt 是「君子協定」 — 守規矩的爬蟲會聽,不守規矩的不會。要做更精細的控制與監測,建議搭配兩個工具:
Cloudflare AI Crawl Control(2025 年下半年正式推出,本文截圖就來自這個面板):在 Cloudflare 主控台「Security → AI Crawl Control」可以看到每隻爬蟲的流量、允許 / 失敗請求數,並對個別爬蟲做「允許 / 封鎖 / 加挑戰」三段式設定。比 robots.txt 強的地方在於:
- 強制執行(不像 robots.txt 是君子協定)。
- 可以對特定路徑或內容類型套用不同規則。
- 可以收費(Cloudflare 的「Pay per Crawl」實驗 — 對 AI 爬蟲收取微額費用,讓內容創作者從訓練資料中獲得收益)。
llms.txt(LLM 索引檔):類似 robots.txt,但用途相反 — robots.txt 告訴爬蟲「別去哪」,llms.txt 告訴 AI「請優先讀這幾頁,這是我品牌的精華」。格式為 Markdown,放在根路徑 https://your-domain/llms.txt。範例:
# 百原科技 Baiyuan Technology
> 台灣首創 AI 能見度監測與優化平台。讓 AI 用正確的事實描述你的品牌。
## Key Facts
- 服務:GEO(生成式引擎優化)、PIF AI、企業 RAG 客服
- 覆蓋:14+ 主流 AI 平台監測(含 ChatGPT、Claude、Gemini、Perplexity、Grok 等)
- 聯絡:02-5568-6586 · [email protected]
## Core Pages
- [關於百原科技](https://www.baiyuan.io/about.html): 公司背景與服務介紹
- [服務項目](https://www.baiyuan.io/services.html): GEO / PIF / RAG 三條產品線
- [常見問題](https://www.baiyuan.io/faq.html): GEO 是什麼、與 SEO 差異、適用對象
## Whitepapers
- [GEO Platform 技術白皮書](https://github.com/baiyuan-tech/geo-whitepaper/releases): 82 頁 / CC BY-NC 4.0
多數 AI 平台(特別是 Anthropic Claude 與 Perplexity)已經明確支援讀 llms.txt,並會優先把這份文件當作品牌的「官方說法」。
進階加碼:AXP 影子文檔(百原科技獨家概念):把幻覺修復後的事實內容,以獨立 HTML 頁面的形式放在 /axp/ 子路徑下,並在 llms.txt 與 sitemap 中明確指引,讓 AI 爬蟲下一輪能讀到「我們已經修正過的正確版本」。這是百原 GEO 平台閉環架構的最後一層輸出。
九、用爬蟲面板做月度健檢的 4 個關鍵指標
設定好 robots.txt、WAF 與 llms.txt 之後,不是一勞永逸。AI 爬蟲生態每三個月就會有大變化 — 新爬蟲冒出、舊爬蟲改 User-Agent、雲端 IP 範圍變動、各家對失敗回應的容忍度調整。你應該把爬蟲面板當作每月例行健檢的對象,重點看下面 4 個指標:
指標 1:訓練爬蟲 vs AI Search 爬蟲的流量比例
健康的比例大約是 訓練爬蟲流量 :AI Search :AI Assistant = 70% :20% :10%(以 KB 計)。如果你的訓練爬蟲流量佔比超過 90%,代表 AI 搜尋還沒「發現你」 — 內容沒被建立到 SearchGPT / Perplexity 索引中,需要主動推送(透過 sitemap、Bing Webmaster Tools 提交、Perplexity 的 publisher program 等)。反過來,如果 AI Search 比例超過 40% 但訓練爬蟲不到 30%,代表你被 GPTBot / ClaudeBot 等訓練爬蟲擋住了,需要檢查 robots.txt 跟 WAF 規則。
指標 2:每隻爬蟲的失敗率(Failed ÷ Total)
整體爬蟲失敗率應該控制在 10% 以下。單一爬蟲失敗率超過 30% 就是警訊。常見成因:頁面回應時間超過 10 秒、被 WAF 攔截、被 Rate Limit 觸發、伺服器回 5xx 錯誤。修復順序:先看伺服器健康(5xx 比例、回應時間),再看 WAF 規則,最後才是 robots.txt。我們最近輔導過一家電商品牌,整體失敗率 45%,原因是 nginx 的 server-side cache 未啟用、首頁回應時間 12 秒,爬蟲 timeout 全部失敗 — 修了 cache 之後失敗率降到 4%,AI 引用率三週內翻倍。
指標 3:「失蹤名單」— 應該有但沒出現的爬蟲
對照本文的 16 隻基本款,每月檢查哪幾隻「應該來但沒來」。常見失蹤狀況:
- GPTBot 連續 30 天 0 流量 → 八成被 robots.txt 或 WAF 擋了。OpenAI 的爬蟲很積極,不可能對一個正常運作的網站完全沒興趣。
- PerplexityBot 流量遠低於 OAI-SearchBot → 可能是內容類型不適合 Perplexity(它偏好深度技術 / 商業 / 研究內容);也可能是被歸類為「重複內容」沒被收錄。
- Claude-SearchBot 完全沒出現 → 正常,因為 Claude 的網路搜尋功能還在推廣,流量本身就小。
指標 4:每月新增的「不認識的爬蟲」
每月會冒出 2–5 隻新的爬蟲。先別急著封鎖,用 User-Agent 字串 Google 一下(或丟給 Claude / ChatGPT 問),確認是哪家的、合法性如何。我們維護的一張內部清單顯示,2024–2026 年新增的合法 AI 爬蟲包括:Diffbot、xAI(Grok)的 X 爬蟲、Cohere 的 cohere-ai bot、Mistral AI、騰訊混元爬蟲、阿里通義千問爬蟲等。新爬蟲的處理原則:先觀察一週流量與行為模式,再決定要不要納入正式名單。
把這四個指標做成月度報表,30 分鐘就能完成一次健檢,比突然發現「我們在 ChatGPT 上消失了」要事半功倍。
十、為什麼是這 16 隻?— 這是 2026 年的「爬蟲基本款」
你可能會問:網路上的爬蟲不只 16 隻,市面上隨便一查都能列出上百種 User-Agent,為什麼這篇文章只挑這 16 隻來講?
答案很直白:這 16 隻不是我們挑的,是它們自己「挑了」我們。
本文所有的數據、流量排行、允許/失敗比例,全部來自百原科技自家兩個站 — www.baiyuan.io(品牌官網,以企業形象與部落格內容為主)和 geo.baiyuan.io(GEO SaaS 平台,含產品介紹、FAQ、文件)— 在 Cloudflare AI Crawl Control 面板上30 天的真實流量合計。換句話說,這是一組典型的「B2B SaaS 品牌站 + 產品站」組合,在沒有特別「招攬」也沒有特別「拒絕」任何爬蟲的中性狀態下,自然出現的爬蟲名單。兩個站合計,正好覆蓋了「行銷內容型」與「產品技術型」兩種網站的爬蟲生態。
這份名單具有兩個重要意義:
- 它就是 2026 年的「爬蟲基本款」。任何一個架在公開網路、有合理 SEO 與內容的台灣中文網站,30 天內大概率都會看到這 16 隻 — 也許名次微調、也許多幾隻區域性的小爬蟲,但這 16 隻是核心結構。你的網站如果缺了其中某幾隻(特別是 GPTBot、ClaudeBot、PerplexityBot 這幾個 GEO 主流通道),那就是個警訊 — 不是 AI 不想抓你,是某個地方(robots.txt、WAF、IP 封鎖規則)把它們擋下來了。
- 它是你做 GEO 決策時必須先盤點的對象。GEO 不是抽象概念,是一個個具體爬蟲是否能正確讀取你內容的總和。先把這 16 隻看懂、設定對,剩下的長尾爬蟲(Yandex、Baidu、Sogou、各種 SEO 工具、學術研究爬蟲等)可以用
User-agent: *的 fallback 規則統一處理。
另一個角度:你可以把這 16 隻當作「AI 時代的 16 個必檢的觸點」。每一隻代表一個 AI 生態系(OpenAI、Anthropic、Google、Microsoft、Meta、Apple、Amazon、ByteDance、Huawei、Perplexity、Common Crawl)對你品牌的認知通道。漏掉任何一個,就等於少了一個 AI 平台對你的曝光機會。
所以這篇文章的本質不是「百原科技 30 天爬蟲報告」,而是「2026 年所有中文網站經營者都應該認識的 16 個 AI 觸點」。看完之後,你應該打開自家 Cloudflare(或同等工具)的爬蟲面板,把這 16 隻一個一個對照過去 — 該開的有沒有開、該限的有沒有限、有沒有意外的「失蹤名單」需要救回來。
十一、AI 爬蟲未來 18 個月的 3 個趨勢
本文寫於 2026 年 5 月,是當下的快照。但 AI 爬蟲生態變化極快,未來 18 個月(到 2027 年底)有 3 個趨勢值得提前佈局:
趨勢 1:Pay-per-Crawl 走向標準化 — 爬蟲訪問將開始「付費」
Cloudflare 在 2025 年下半年推出的「Pay per Crawl」實驗,允許網站對 AI 爬蟲的每次訪問收取小額費用(透過 HTTP 402 Payment Required 機制)。這個概念正在被產業逐漸接受 — OpenAI、Anthropic 都已表態願意在「合理價格區間」內為高品質內容付費。預計到 2027 年,新聞媒體、學術出版、專業內容(法律 / 醫療 / 財經)將普遍對 AI 爬蟲收費。中小企業則建議維持免費開放(你需要的是曝光不是抽成),但要開始把「Pay per Crawl」當作可用工具備著。
趨勢 2:「Verified Bot」白名單將變成 GEO 必要門票
主流 CDN(Cloudflare、Fastly、Akamai)正在建立越來越嚴格的「驗證爬蟲」名單 — 只有經過密碼學簽章 / IP 驗證的爬蟲才被視為「可信」,否則一律按可疑流量處理。對網站經營者來說,這是好事 — 偽冒 Googlebot / GPTBot 的惡意爬蟲會被自動過濾。但反過來,不在驗證名單上的合法新爬蟲(例如某新創 AI 公司)會被誤殺。建議每月檢查 Cloudflare 的「Verified bots」清單變化,新增的合法爬蟲記得手動加白名單,否則會錯過早期 AI 公司的曝光。
趨勢 3:「結構化內容」優先順序將大幅提升
2026 年我們已經看到,AI 爬蟲對「結構化內容」(含 Schema.org JSON-LD、清楚的 H1-H6 階層、語意 HTML、表格、列表)的偏好越來越明顯。GPTBot 與 ClaudeBot 在抓取相同網域時,對有完整 Schema 標記的頁面,抓取頻率比沒有的高出 2–3 倍。預計到 2027 年,沒有結構化標記的純文字頁面,將被 AI 爬蟲視為「低品質訊號」而降低抓取優先序。這也是百原科技 GEO 平台特別強調「Schema.org 三層實體」與「AXP 影子文檔」的原因 — 它們本質上都是把內容「翻譯成 AI 看得懂的格式」。
把這 3 個趨勢納入規劃,你的 GEO 佈局就能領先大多數品牌 12–18 個月。
十二、結語:把爬蟲面板當作品牌的雷達
過去十年,多數品牌只把搜尋引擎優化(SEO)當成一件事 — Google 排名上去就是贏。2026 年之後,這件事被拆成了兩個並行的戰場:傳統 SEO(Google / Bing 排名)與 GEO(AI 答題中的引用率)。
而 AI 爬蟲面板,就是 GEO 戰場的雷達。每一隻爬蟲的流量、允許 / 失敗比例、訪問頻率,都在告訴你:
- 誰對你感興趣(高流量的爬蟲 = 高重要性的 AI 生態);
- 誰被你拒於門外(高失敗率 = WAF 規則太嚴 / 頁面太慢 / robots.txt 寫錯);
- 哪些 AI 平台會在下次答題中提到你(AI Search 與 Assistant 的抓取頻率是先行指標)。
本文把 16 隻爬蟲的身份、規則、設定建議全部講完。你接下來可以做三件事:
- 檢查自家 robots.txt:對照本文模板,看有沒有誤封 AI Search / Assistant;有沒有放任 Meta-ExternalAgent / Bytespider 吃頻寬。
- 啟用 Cloudflare AI Crawl Control(或同等工具如 Fastly、AWS WAF Bot Control):把爬蟲流量視覺化,定期檢查趨勢。
- 建立
llms.txt:給 AI 一份你品牌的「官方說法」,引導 AI 用正確事實描述你。
想知道目前你的品牌在 14 個主流 AI 平台上的真實能見度?百原科技提供 60 秒免費 AI 能見度健檢:輸入品牌名稱,即時掃描 ChatGPT、Claude、Gemini、Perplexity、Grok、DeepSeek、Qwen 等 14 個 AI 平台,告訴你哪些有提到你、哪些講錯了你的資訊。
👉 立即免費診斷:geo.baiyuan.io/diagnose
延伸閱讀:
- 客戶不再 Google 你,他們開始問 ChatGPT — 你準備好了嗎? — 寫給中小企業主的 GEO 入門
- GEO 的本質:你改變不了 AI 的演算法,但你能改變 AI 對你的認知 — GEO 邏輯深度觀點
- 《百原 GEO Platform 技術白皮書》精華導讀 — 整套 GEO 平台的工程實踐(含 82 頁 PDF 下載)
關於百原科技
百原科技(BaiYuan Technology)是台灣首創的 AI 能見度監測與優化平台。我們相信,AI 時代的品牌競爭,不是誰的廣告預算大,而是誰的事實架構對。我們的使命是讓台灣品牌第一次看見自己在 AI 世界的樣子 — 並且有能力改變它。
📍 新北市中和區景新街 338 號 12 樓
📞 02-5568-6586
✉️ [email protected]
🌐 geo.baiyuan.io