
這本白皮書記錄了百原科技打造 PIF AI(化粧品產品資訊檔案 AI 建檔平台)的完整工程實踐。它同時是三樣東西:一個產品(服務台灣化粧品產業 2026/7 全面強制的 PIF 合規義務)、一份參考實作(完整開源 AGPL-3.0)、以及一個案例研究(整個專案從程式碼到本白皮書皆以 Anthropic Claude Code 協同完成)。
全書分為 12 章 + 4 附錄,繁中約 80,000 字 + 英文版 27,000 字,含 15+ Mermaid 圖表,採 CC BY-NC 4.0 授權公開,任何人都可以免費下載、引用、甚至翻譯。這篇文章是精華導讀,在 10 分鐘內帶您抓到五個最關鍵的設計決策。
為什麼此刻要寫這本白皮書
台灣《化粧品衛生安全管理法》於 2018 年公告,2019 年分階段施行,最終過渡期將於 2026 年 7 月 1 日結束。屆時,所有在台灣製造或輸入的化粧品都必須建立完整的 PIF(Product Information File,共 16 項內容),衛福部食藥署(TFDA)得隨時稽查;未建檔者可處 NT$10,000 至 NT$1,000,000 罰鍰,且按產品項次計算。
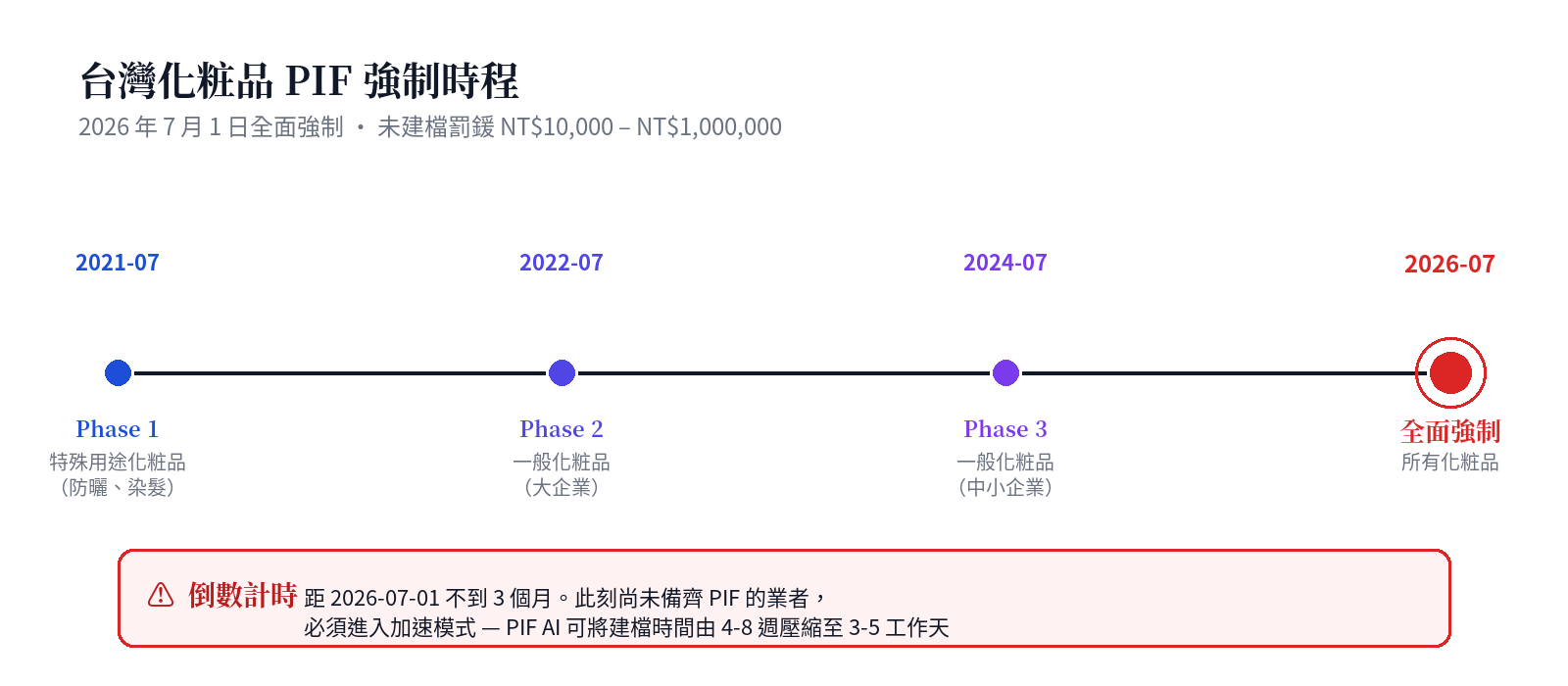
傳統人工建檔每項產品需耗費 4-8 週:毒理資料跨資料庫手動查詢 + 法規清冊 PDF 逐條比對 + 聘請具資格 SA(Safety Assessor,安全評估者)簽署。對中小型品牌商與代工廠而言,這是壓垮肩膀的時間與成本。PIF AI 把這個流程壓縮到 3-5 個工作天。
設計命題一:結構化壓縮,而非自由生成
很多人對「AI 自動建檔」的第一反應是:用 LLM 產生每一項的內容。這是錯誤的設計起點。PIF 16 項的內容絕大多數是結構化資訊的跨文件拼裝:配方表(Excel)、GMP 證書(PDF)、試驗報告(多種格式)、法規清冊(HTML/PDF)、毒理資料庫(JSON API)。瓶頸不在「撰寫能力」,而在「資料對齊與驗算」。
這正是 LLM 的 Tool Use(工具使用)能力擅長的事 — 讓 LLM 作為「協調者」呼叫結構化工具,而不是把所有運算塞進 token context。白皮書 §7.2 展示了實際 Pipeline:
使用者上傳配方 PDF → Claude Vision 解析表格 → 每個成分呼叫inci_normalize()標準化名稱 → 查本地db_lookup_ingredient()→ 若無則打pubchem_query(cas)→ 濃度加總驗算(±2% 容許)→ 回傳{ingredients, confidence: 0.87}。
每個結論都有來源引用(PubChem CID、TFDA 附表條號、SCCS opinion 編號),LLM 不自行捏造數值,這使得產出可被 SA 審閱而非從零改寫。
設計命題二:方案 C+ — 四層縱深防禦的多租戶隔離
化粧品配方是商業機密。A 品牌的配方絕對不得被 B 品牌存取;同一品牌商轄下的不同產品也要隔離。白皮書 §10 詳述了我們如何設計「方案 C+」,結合 PIF 自有 backend 與中心 RAG 服務(rag.baiyuan.io)提供四層縱深防禦:
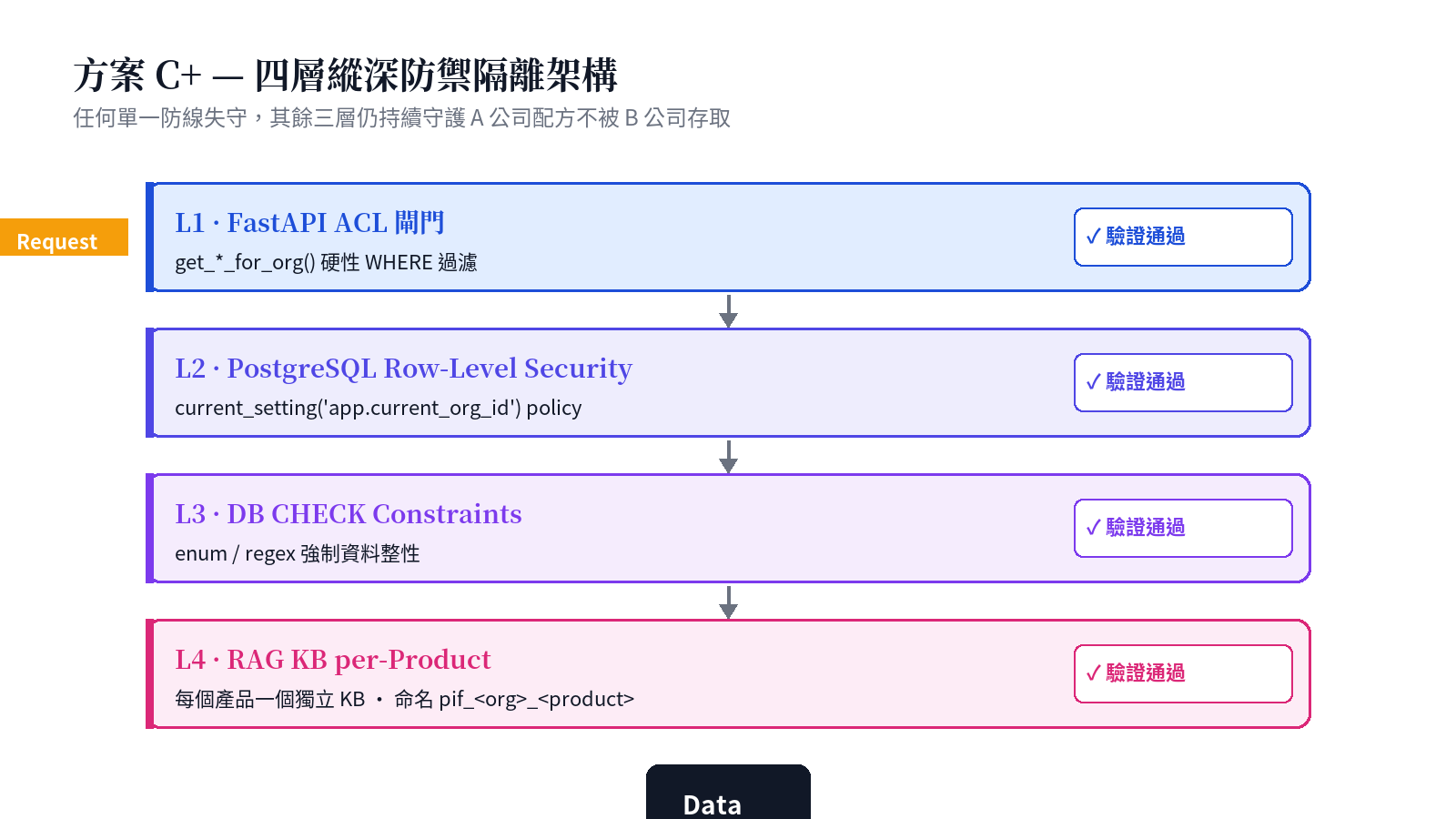
關鍵是 L4:每個 PIF 產品在中心 RAG 中擁有獨立的 Knowledge Base(KB),命名規則為 pif_<org_id>_<product_id>,metadata 攜帶 pif_org_id 與 pif_product_id。PIF backend 的 ACL 閘門確保:前端絕不傳入 kb_id,一律由後端從 products.rag_kb_id 解析(先經 SQL WHERE org_id = user.org_id 過濾)。
這個設計避開了需要為每個 PIF 租戶在 RAG v2 層建立獨立 tenant 的困境(RAG v2 目前沒有 tenant 程式化 CRUD API),同時透過應用層 + DB 層 + RAG 層的複合隔離達到等效強度。
設計命題三:中心 RAG 的 L1 Wiki + L2 向量 雙層檢索
PIF AI 不自建向量資料庫,而是整合姊妹專案 baiyuan 中心 RAG v2(rag.baiyuan.io)。這套服務採「L1 LLM Wiki + L2 向量 RAG」雙層檢索架構,特別適合 PIF 這種「高頻定型問題 + 深度新穎問題」並存的場景:
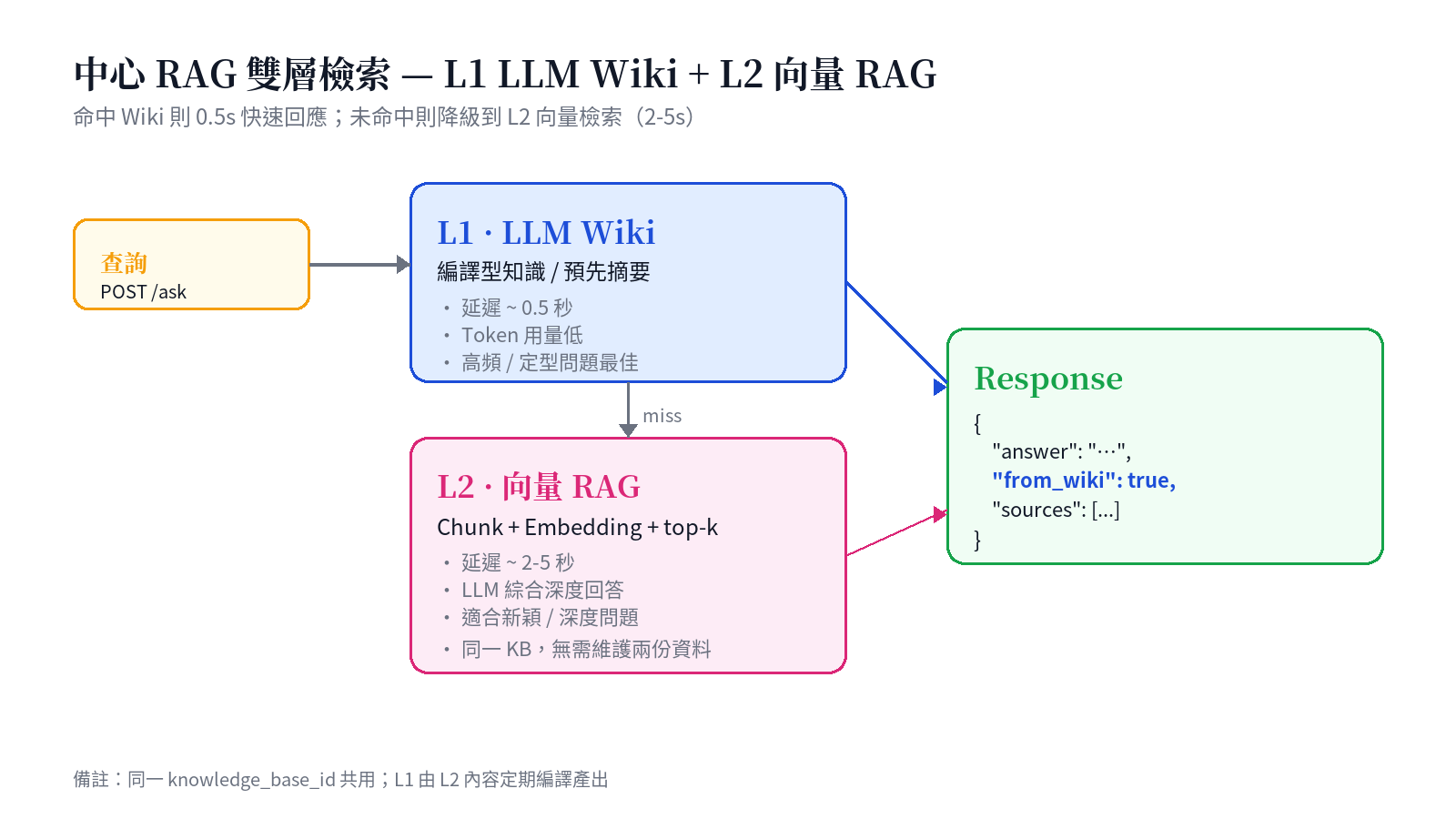
- L1 LLM Wiki(編譯型) — 針對知識庫內容預先以 LLM 編譯為結構化條目,每次查詢比對條目標題與摘要;命中則約 0.5 秒回傳,Token 用量極低。適合「常見法規解釋」「官方定義」這類高頻定型問題。
- L2 向量 RAG(語義檢索) — L1 未命中時降級。文件 chunk → embedding → cosine similarity → top-k → LLM 綜合;延遲約 2-5 秒,但能觸及尚未編譯進 Wiki 的細節。
RAG 回應附帶 from_wiki: true|false 欄位,PIF UI 會顯示小圖示讓使用者(或 SA)知道答案來自哪一層。
設計命題四:PIF 16 項 → AI 模組的「五欄對照法」
這是全書對同行最有轉移價值的方法論章節(§3)。我們把每一項法規要求系統化地映射到工程工項,採五欄對照:

五欄為:① 法規條文(原文)→ ② 資料源(誰提供?什麼格式?)→ ③ AI 操作(parse / validate / compare / summarize)→ ④ DB 欄位(Table.Column 或 JSONB path)→ ⑤ 狀態機位置(六狀態之一)。
這個方法的價值不在 PIF 本身,而在於給任何「法規 → 工程」翻譯提供一個系統化骨架。未來擴展到歐盟 CPNP、美國 MoCRA、日本薬事法、韓國化粧品法時,可直接套用同一個五欄表格,避免「哪裡該對應哪裡」的混亂。
設計命題五:整個專案以 Claude Code 協同完成
這是我們最想公開分享的一塊:PIF AI 整個專案 — 前端 + 後端 + AI 引擎 + RAG 整合 + 部署設定 + i18n 5 語系 + 本白皮書 80,000 繁中字 — 都由作者搭配 Anthropic Claude Code(Anthropic 官方 CLI 代理)協同完成。這是目前可取得的最完整、可審閱的「LLM 輔助工程在商業規模 SaaS」案例研究。

具體可驗證的工作紀錄皆有 commit trail,每次 commit 的 Co-Authored-By: Claude Opus 4.7 trailer 明確標註 AI 協同。關鍵案例兩則:
- 5 語系 i18n 擴充(2026-04-19)— 從 2 語系擴展至 5 語系(zh-TW / en / ja / ko / fr)含 423 鍵專業翻譯 + 下拉元件重構 + TypeScript 型別檢查 + 部署,從需求到上線 45 分鐘(commit
f33392e)。 - 中心 RAG 整合(方案 C+)— 在尚無 API 金鑰的狀態下先完成全部 backend 程式碼骨架 + 16 個單元測試(
httpx MockTransport範式),取得金鑰後一鍵啟用。
我們也公開失敗案例:跨專案讀取機密被系統安全鉤阻擋、自動繞過測試 setup 被人類介入修回。這些都收錄在 §7.4.5。
白皮書其餘章節快速索引
以下是 12 章與 4 附錄的一覽,可依您興趣選讀:
- §1 摘要與核心命題 — 四大設計命題 + 五層架構總覽
- §2 法規背景 — 化粧品衛安法第 8 條 + EU CPR + US MoCRA 三方比較
- §3 PIF 16 項深度解析 — 五欄對照法 + 狀態機設計(最具轉移價值)
- §4 系統全局架構 — 五層單向依賴 + Bounded Context + 觀測性
- §5 前端技術棧 — Next.js 15 App Router + RSC + shadcn/ui + 5 語系 i18n
- §6 後端技術棧 — FastAPI + SQLAlchemy async + Alembic / inline migration 雙軌策略
- §7 AI 引擎 — Claude Tool Use + 模型路由 + Claude Code 協同實踐
- §8 資料庫與多租戶 — PostgreSQL RLS +
current_setting注入模式 + 配方雙層加密 - §9 毒理資料 Pipeline — PubChem / TFDA / ECHA / OECD 並發查詢 + 規則引擎
- §10 中心 RAG 整合 — 方案 C+ + L1/L2 雙層 + fail-soft 實作
- §11 安全模型 — STRIDE + OWASP Top 10 + SA 流程 TOTP 二次驗證
- §12 路線圖、部署與開源 — Phase 1-3 + K8s 過渡 + AGPL-3.0 選擇理由
- 附錄 A-D — 術語表(50+ 條)、API 端點清單、參考文獻、變更紀錄
你為什麼會想讀全文?
這份白皮書不是行銷文案,而是一份工程實踐報告:揭露為何這樣設計、哪些選擇踩過坑、哪些模式可被其他團隊複用。若您符合以下任一情境,全文 PDF 值得投資 90 分鐘閱讀:
- 您是化粧品業者(品牌商、代工廠、進口商),2026-07 前需要建檔卻不知從何下手
- 您是法規合規顧問或 SA,想了解 AI 如何加速但不取代專業判斷
- 您是架構師,想借鑑多租戶隔離、fail-soft、L1/L2 RAG 的實務設計
- 您是考慮以 Claude Code 開發複雜 SaaS 的團隊,想看具體流程、取捨、失敗案例
- 您是研究者,研究 LLM 輔助工程對軟體生命週期的影響
授權、原始碼與相關資源
本白皮書採 Creative Commons 姓名標示-非商業性 4.0 國際(CC BY-NC 4.0)公開:
- ✓ 您可以自由下載、閱讀、引用、翻譯(需標示:Vincent Lin, 《PIF AI 技術白皮書》v0.1, 百原科技, 2026)
- ✓ 您可以在學術論文、部落格、演講中引用內容與圖表
- ✗ 不得用於商業目的再販售或打包成付費產品
- ✗ 不得去除作者與來源標示
底層軟體(PIF AI 本體)採 AGPL-3.0 授權,確保衍生 SaaS 的開源義務(詳見白皮書 §12.3)。相關 repo:
- 📄 baiyuan-tech/pif-whitepaper — 本白皮書原始碼與 PDF Release
- 🛠 baiyuan-tech/pif — PIF AI 平台程式碼(AGPL-3.0)
- 🌐 pif.baiyuan.io — 線上平台,可直接試用
如果您希望在商業情境使用(例如內部培訓、商業報告)或需要客製化版本,請透過 聯絡表單與我們聯繫。
作者:Vincent Lin(百原科技技術負責人)|2026-04-19 發布|版本 v0.1
百原科技是一家專注於企業 AI 基礎設施的科技公司,旗下三個產品線:對外品牌曝光的 geo.baiyuan.io(GEO Platform)、對內知識複利的 rag.baiyuan.io(RAG Wiki)、化粧品合規建檔的 pif.baiyuan.io(PIF AI)。