
這本白皮書記錄百原科技於 2024–2026 年打造百原 RAG 知識庫平台的工程實踐。它不是單一產品的使用說明,而是一套共用基礎設施:同時為「百原 AI 客服 SaaS」、「百原 GEO Platform」、「百原 PIF AI」三條產品線提供知識檢索能力。
全書共 12 章 + 4 附錄、繁中 ~45,000 字,並同步提供 英文 + 日文版 PDF,採 CC BY-NC 4.0 授權公開。本文在 10 分鐘內帶您抓到五個最關鍵的設計決策。
為什麼要寫這本白皮書
白皮書開場用「知識庫的黑暗森林」來描述當前企業 RAG 導入的真實處境:把 PDF 丟進 ChatGPT,第二天被客戶發現 AI 講錯了價格、講錯了退貨政策、把 A 客戶的機密洩漏給 B 客戶。問題不在 prompt 沒調好,而在基礎設施。
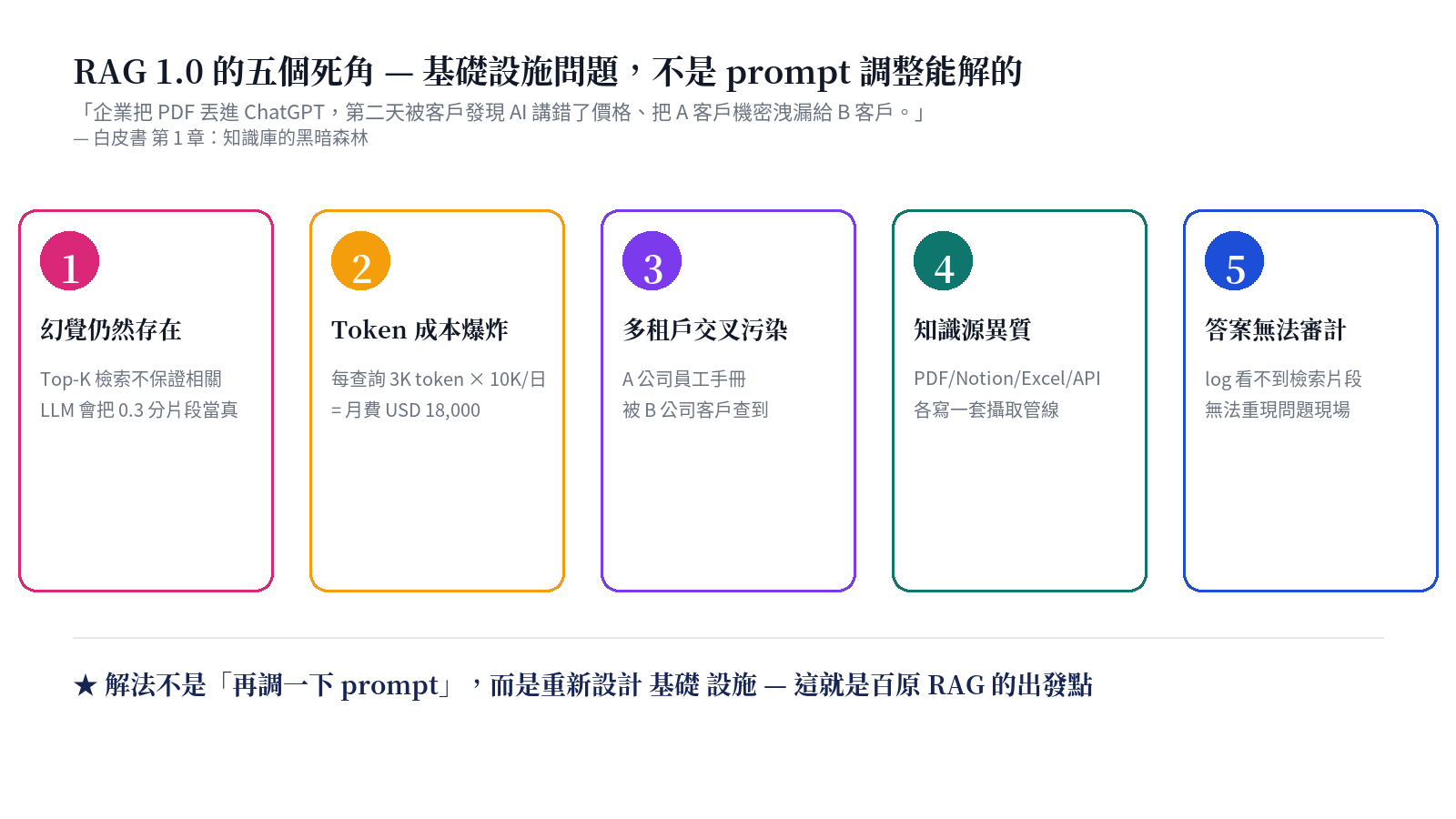
這五個死角彼此勾連:幻覺的成因部分是 Top-K 檢索的相關度不夠,而提高相關度需要混合檢索,但混合檢索又會增加 Token 成本;租戶污染的根因是一個 embedding index 沒分 collection,改用 partition 後又影響了 fallback 邏輯。白皮書主張:**「把這五件事當成同一件事」設計,才有工程解**。
設計命題一:雙層檢索架構 — 79% 成本降低的核心
白皮書 §3 + §4 + §5 是整本書的核心三章,合起來解釋一個問題:**在 SaaS 規模下,RAG 如何做到「既便宜又準確」**?答案是**不要每次都打 LLM**。
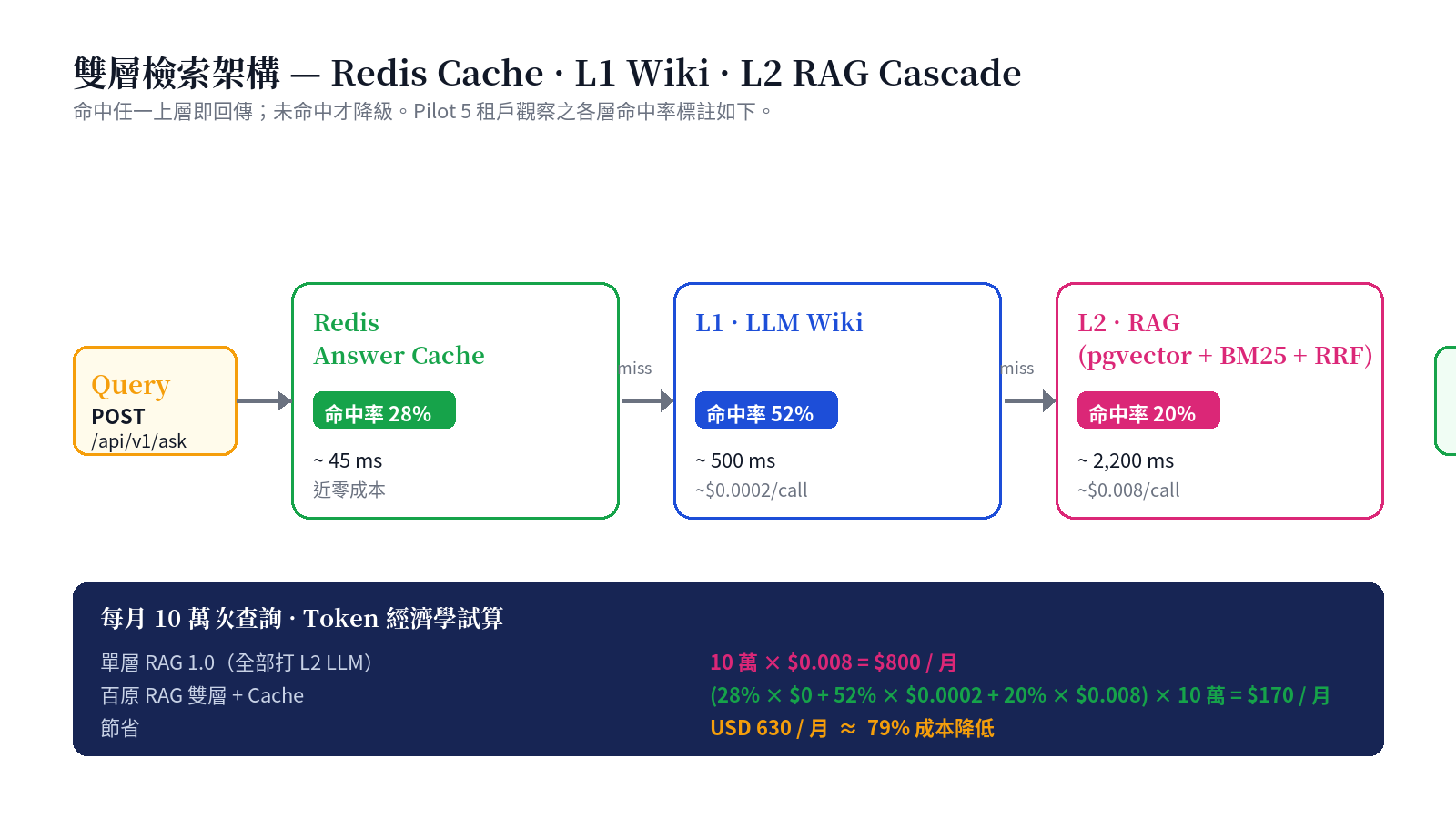
- Redis Answer Cache(~45 ms,近零成本):完全相同的問題直接命中快取,**28% 的流量在此被攔截**
- L1 · LLM Wiki(~500 ms,~$0.0002/call):預先編譯好的「DB 化知識摘要」,靠結構化比對就能回答,**52% 的流量在這層解決**
- L2 · RAG(~2,200 ms,~$0.008/call):真正的 pgvector + BM25 + RRF 混合檢索 + LLM 綜合。只有 20% 的流量會用到這層
每月 10 萬次查詢的賬:單層 RAG 1.0 要 USD 800;雙層 + Cache 只要 USD 170。79% 成本降低,而且 80% 的查詢在 500ms 內回應。
這不是 toy example — 白皮書 §11 揭露 Pilot 期 12 家租戶的真實命中率區間(40-70% L1 命中率、12-31% Cache 命中率),並把好看與難看的都寫進去。
設計命題二:pgvector + BM25 + RRF — 為什麼不用獨立向量庫
市面多數 RAG 方案用 Pinecone、Weaviate、Qdrant 等獨立向量資料庫。百原 RAG 選把向量直接存在 PostgreSQL(透過 pgvector extension),並與 BM25 全文檢索在同一個 DB instance 內做 Reciprocal Rank Fusion(RRF)。理由於 §4.2 給出完整論證:
- 統一 transaction 邊界 — 向量寫入與 metadata 寫入在同一交易,天然一致
- 降低營運成本 — 少一個要監控、備份、升級的系統
- 多租戶天然對齊 — 用 PostgreSQL partition + Row-Level Security 同時處理向量與關聯資料
- 混合檢索更準 — BM25 擅長「稀有關鍵字」(如產品型號、法規條號)、向量擅長語義,RRF 把兩者結果融合
- 遷移成本低 — 未來若真的撞到 pgvector 天花板,只需把 vector 欄位改 API 而不用重寫業務邏輯
白皮書提出一個實測觀察:在 Pilot 期「產品型號 + 中文描述混合查詢」情境下,**純向量檢索 recall@5 為 72%,加上 BM25 + RRF 後提升到 91%**。這在法規、醫療、專業技術文檔等「關鍵字密集」場景特別關鍵。
設計命題三:三層租戶隔離 — SaaS 的資安底線
A 公司的員工手冊絕對不可被 B 公司的客戶檢索到。白皮書 §6 描述三層縱深防禦:
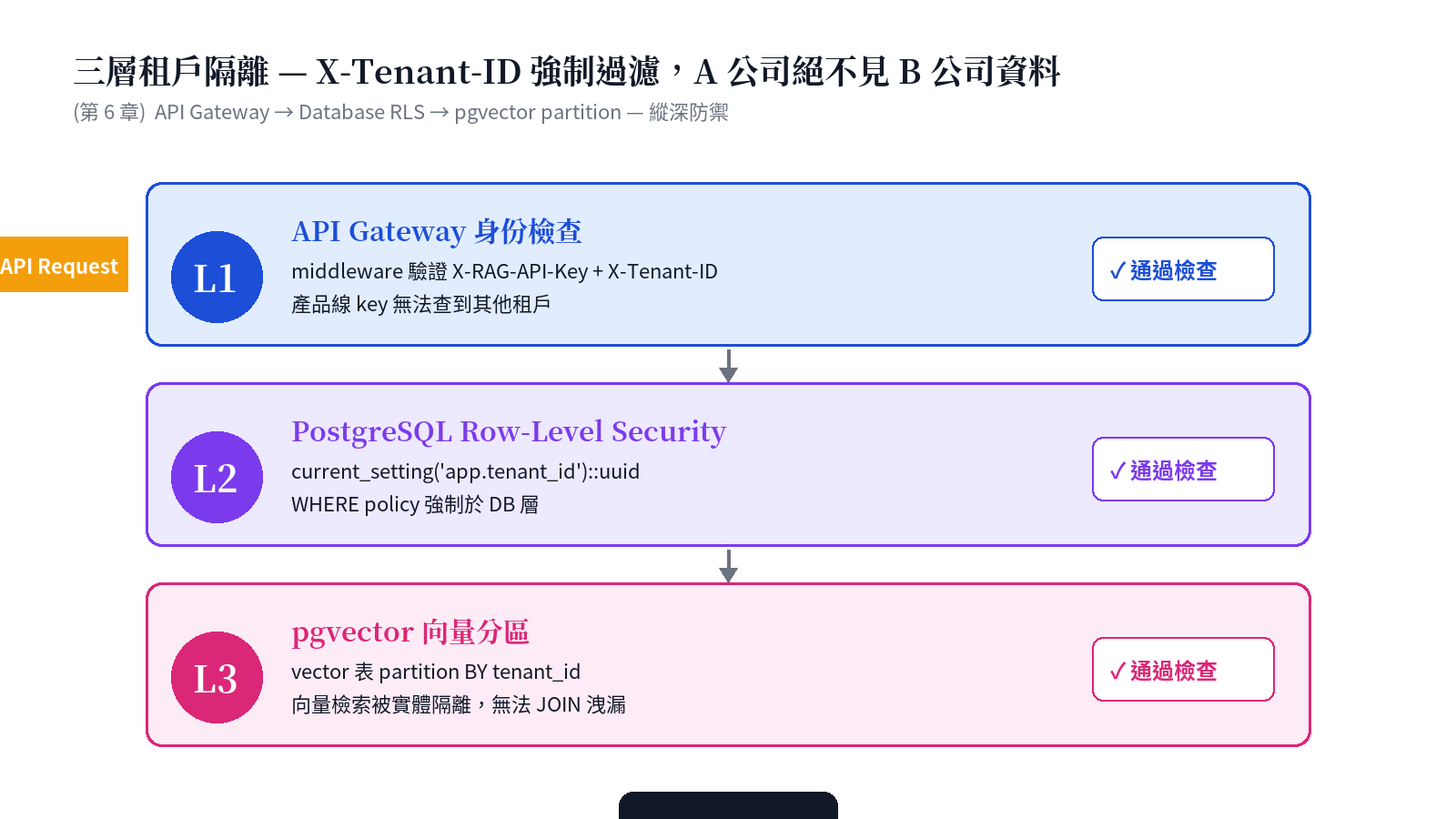
- L1 · API Gateway:middleware 驗證
X-RAG-API-Key+X-Tenant-ID雙 header。產品線 key 即使拿到手,也無法查到其他租戶 - L2 · PostgreSQL Row-Level Security:每個 session 啟動時注入
app.tenant_id,WHERE policy 於 DB 層強制。應用層 bug 也無法跨租戶 - L3 · pgvector 向量分區:向量表 partition BY
tenant_id,實體隔離;查詢計畫無法 JOIN 到其他分區
任何單一防線失守,其餘兩層仍持續守護。這是「縱深防禦」而非「最強單點」— 因為單點永遠會被繞。
設計命題四:單一基礎設施 · 三條產品線共用
這份白皮書最值得其他 AI 團隊借鑑的一點:**不要為每條產品線各自建一套 RAG**。
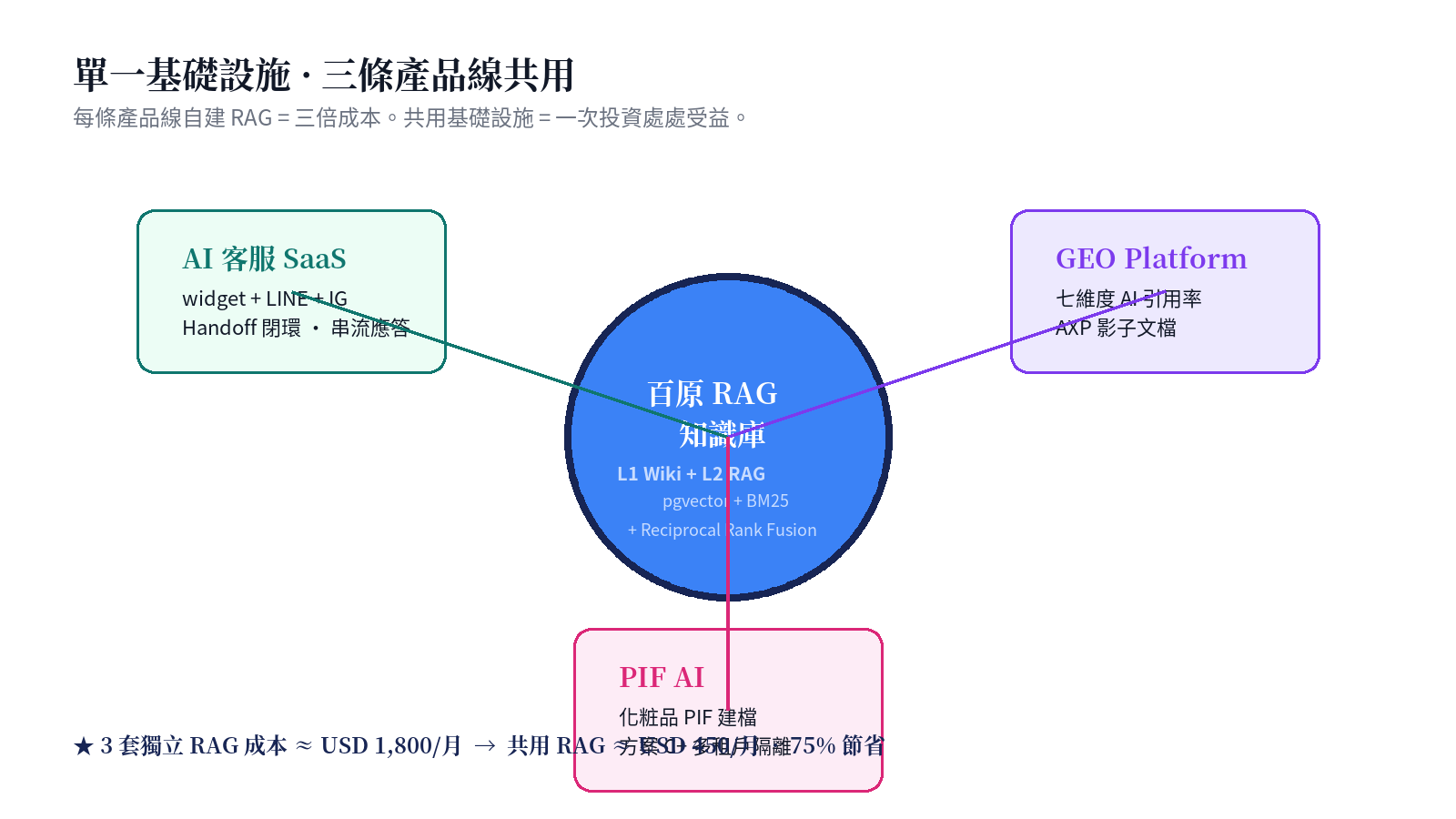
三條產品線的業務邏輯差異極大,但「給 LLM 餵結構化知識片段 + 維護多租戶隔離」這件事是**共通的**:
- AI 客服 SaaS(§8, §11-A, §11-B)— 線上客服 widget + LINE + IG;用 Stream 應答 + Handoff 真人 loop
- GEO Platform(§9)— 七維度 AI 引用率評分的「品牌實體」知識由 RAG 提供;Schema.org 三層實體與 RAG KB 相互索引
- PIF AI(§10, §11-C)— 化粧品 PIF 16 項資料建檔;每個產品一個 KB(方案 C+),毒理資料與法規條文以 L1 Wiki 形式預編譯
Token 經濟學不只發生在 Cache/L1/L2 的三階 cascade — 也發生在「一次基礎設施投資、三條產品線享用」這個組織層面。3 套獨立 RAG ≈ USD 1,800/月 → 共用 RAG ≈ USD 450/月,75% 組織層級的節省。
設計命題五:真實租戶觀察 — 匿名但不粉飾
白皮書 §11 記錄 Pilot 期 12 家真實租戶的數字,聚合呈現、已去識別化:
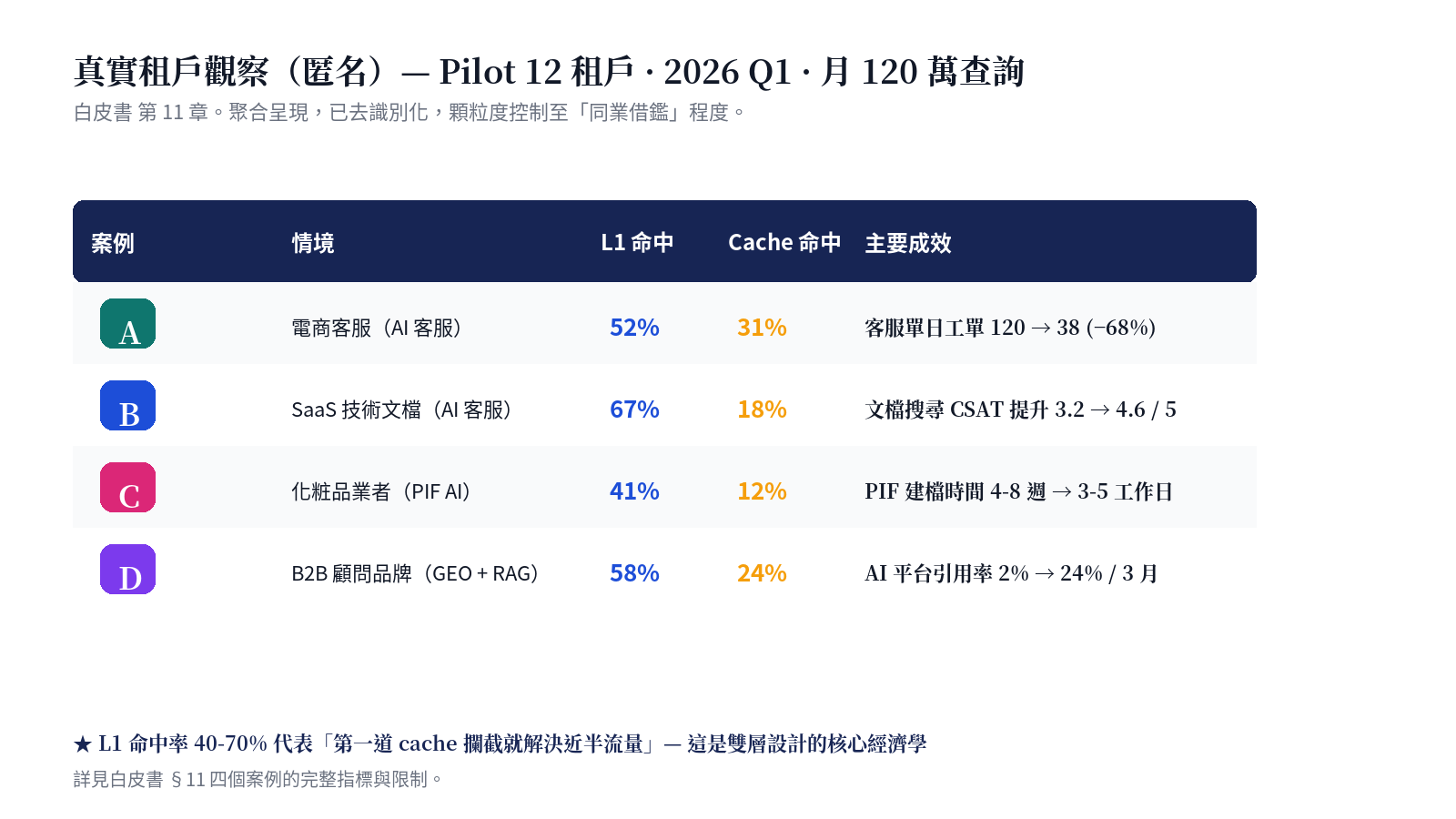
這章刻意收錄 2 個「沒那麼漂亮」的案例(§11.5、§11.6 的反思):**L1 命中率 40% 的案例**(法規產業、查詢高度特化,編譯器要做更多工)、以及**一次 RAG 回答錯誤引發小型事件的還原**(§11.6.3,包含如何從 audit log 追溯 + 如何在 Wiki 編譯器加入該類型的矯正規則)。
「數字不會說謊。但會選擇性沉默。本章把好看與難看的都寫出來。」— 這是白皮書第 11 章的開場白。
白皮書其餘章節快速索引
- §1 知識庫的黑暗森林 — RAG 1.0 的五個死角與基礎設施層的回應
- §2 系統總覽 — 9 階段請求路徑、Schema 全景、組件分工、技術選型決策表
- §3 L1 Wiki — DB 化知識快取的編譯器、更新觸發、失效策略
- §4 L2 RAG — pgvector + BM25 + Reciprocal Rank Fusion 實作與調參
- §5 Fallback 與 Token 經濟學 — 成本/延遲模型、Multi-Provider 路由、動態降級
- §6 三層租戶隔離 — API Gateway / RLS / pgvector partition 的工程合力
- §7 知識攝取(Ingestion) — PDF/Notion/Excel/Web 四種來源的統一管線
- §8 Stream + Handoff — 串流應答、真人客服 loop、狀態機
- §9 與 GEO Platform 的整合 — 品牌實體共用、Schema.org 互連
- §10 與 PIF AI 的整合 — 法規型垂直領域、產品級 KB、方案 C+
- §11 真實租戶觀察 — 4 個案例、好看與難看的都寫
- §12 限制與未來工作 — 目前壓力點、roadmap、希望社群挑戰的假設
- 附錄 A-D — 術語表、API 端點、參考文獻、圖表索引
你為什麼會想讀全文?
這份白皮書不是 RAG 教學、也不是產品推廣,而是一份**可重現的工程實踐報告**:揭露為何這樣設計、哪些選擇踩過坑、哪些模式可被其他團隊複用。若您符合以下任一情境,全文 PDF 值得投資 100 分鐘閱讀:
- 您是 CIO / CTO,正在評估「內部自建 RAG」vs「採購現成 SaaS」
- 您是架構師,想理解 L1 Wiki + L2 RAG 雙層設計的動機與數字
- 您是後端工程師,想看 pgvector + BM25 + RRF 混合在 PostgreSQL 內如何組裝
- 您是多產品線公司的技術主管,正在思考是否該把 AI 基礎設施橫向共用
- 您是 AI / 學術研究者,關心工程化 RAG 系統在 SaaS 情境下的真實表現
授權、原始碼與相關資源
本白皮書採 Creative Commons 姓名標示-非商業性 4.0 國際(CC BY-NC 4.0)授權。
- 📄 baiyuan-tech/rag-whitepaper — 本白皮書原始碼 + 三語 PDF Release
- 📄 baiyuan-tech/geo-whitepaper — 姊妹作:GEO Platform 白皮書
- 📄 baiyuan-tech/pif-whitepaper — 姊妹作:PIF AI 白皮書
- 🌐 rag.baiyuan.io — RAG 引擎產品頁
- 🌐 geo.baiyuan.io · pif.baiyuan.io — 姊妹產品
如需商業授權、客製化導入或內部培訓,請透過 聯絡表單與我們聯繫。
作者:Vincent Lin(百原科技技術負責人)|2026-04-20 發布|版本 v1.0-draft
百原科技是一家專注於企業 AI 基礎設施的科技公司,旗下三個產品線:對外品牌曝光的 geo.baiyuan.io(GEO Platform)、對內知識複利的 rag.baiyuan.io(RAG Wiki)、化粧品合規建檔的 pif.baiyuan.io(PIF AI)。