你的品牌不是輸給競爭對手,是輸給「不存在」本身。
一份基於 8 篇國際學術論文,為台灣 167 萬家中小企業而寫的 AI 時代生存指南。
關鍵詞:Generative Engine Optimization、GEO、AI 品牌能見度、Existence Gap、Data Moat、MAEE 框架、台灣中小企業
序言:一個讓人不寒而慄的下午
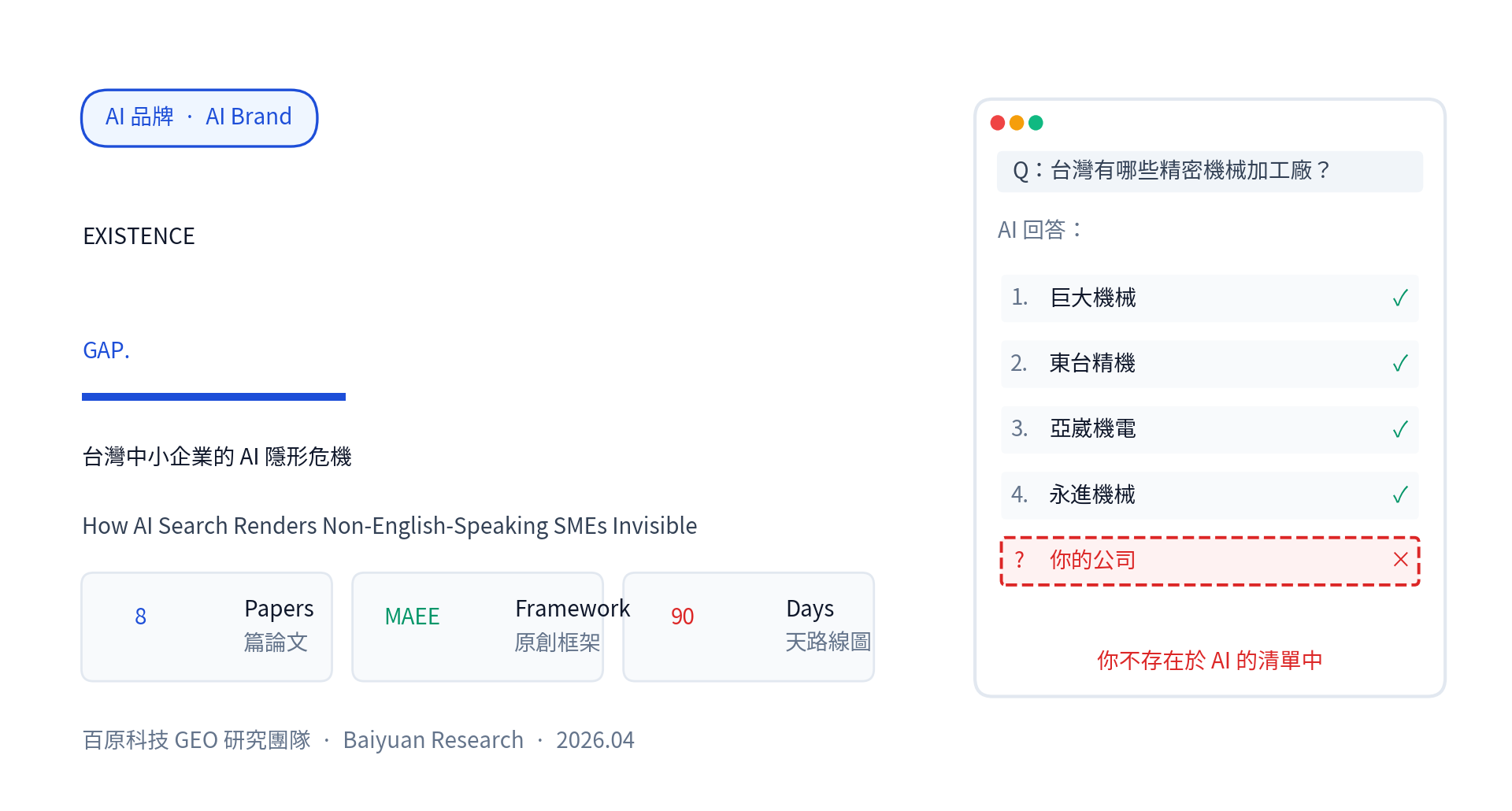
2026 年 3 月某個下午,一家在台中經營 28 年的精密機械廠老闆,第一次認真地打開 ChatGPT。
他輸入一個簡單的問題:「台灣有哪些值得推薦的中小型 CNC 加工廠?」
ChatGPT 給出了一份條理分明的清單。北部 5 家、中部 8 家、南部 4 家。每家都有完整的介紹:成立時間、主要產品線、技術強項、客戶案例。文字流暢,看起來權威。
老闆從頭到尾看了三遍,找不到自家公司的名字。
他不死心,換個問法:「台中精密機械加工廠推薦。」結果一樣。「Tier 1 汽車零組件供應商台灣」、「航太級鋁合金加工廠」——每一個他公司明明符合資格的查詢,AI 都當他不存在。
這家公司年營收 4 億新台幣,全廠 80 個員工,五軸加工機 12 台,TS 16949 認證、AS 9100 認證齊全,外銷美日德三大市場,已經連續 11 年是全台百大隱形冠軍。
但對 ChatGPT 來說,他不存在。對 Claude 來說,他不存在。對 Gemini、Perplexity、Grok 來說,他全部不存在。
這位老闆當天回到家,跟太太說:「我以前以為 AI 只是個工具。今天才發現,它是新的市場——而我們連入場券都沒有。」
這不是個別案例。這是台灣 167 萬家中小企業,正在發生的集體失蹤事件。
為什麼你需要讀完這篇文章
如果你是:
- 企業主或創辦人:你會理解為什麼 AI 不認識你,這對營收的長期影響,以及該怎麼開始補救。
- 行銷主管或 CMO:你會拿到 8 篇國際學術論文的核心發現、5 個立即可執行的策略、3 個你過去從未聽過的關鍵指標。
- 數位轉型負責人:你會看到一個系統化的框架(MAEE),告訴你按什麼順序、做什麼事、解什麼問題。
- 競爭對手是大品牌的中小企業:你會發現一條「繞過大品牌資源優勢、用結構性策略勝出」的路徑。
這篇文章 2 萬字,分為 9 個章節,建議你先看完序言、第一章、第五章,再決定要不要全部讀完。如果你決定全讀,請給自己一杯咖啡的時間——這篇文章值得。
第一章:什麼是 Existence Gap(存在斷層)
1.1 概念的源起
「Existence Gap」(存在斷層)這個詞,第一次正式出現在學術文獻中是 2026 年 1 月。
這篇論文題為《Cultural Encoding in Large Language Models: The Existence Gap in AI-Mediated Brand Discovery》(大型語言模型中的文化編碼:AI 中介品牌發現中的存在斷層),編號 arXiv:2601.00869。
論文的核心論點極為簡潔,卻擊中了所有 AI 時代品牌策略的根基:
當 AI 成為主要的資訊發現介面時,未被編碼到 AI 訓練資料中的品牌將面臨「存在斷層」:無論產品品質如何,它們在 AI 回答中根本不存在。
它說的不是「AI 不推薦你的品牌」(recommendation gap),也不是「AI 給你品牌的描述不準確」(accuracy gap),而是更根本的——AI 認為你根本不存在。
從 AI 的視角,你不是輸給競爭對手,你是輸給「不存在」本身。
1.2 三種能見度狀態的根本差異
一個品牌在 AI 系統中,可能處於三種狀態之一:
狀態 A:完全不存在(Existence Gap)
當用戶問 AI 一個你應該被提到的問題時,AI 根本不會輸出你的品牌。它甚至不知道有「你」這個實體存在。
例子:問「台灣有哪些優秀的 SaaS 新創?」,AI 列了 10 家,沒有你。但你的產品其實非常符合「台灣 SaaS 新創」的定義。
狀態 B:存在但不被推薦(Recommendation Gap)
AI 知道你存在,能回答關於你的事實問題(成立時間、產品線等),但在推薦類問題中不會主動提到你。
例子:問「百原科技是什麼公司?」,AI 給出正確答案。但問「台灣有哪些 GEO 服務商?」,AI 的清單裡沒有百原。
狀態 C:存在且被推薦(Active Citation)
AI 在相關推薦類問題中主動提到你,並給出準確的描述。

90% 以上的台灣中小企業,連狀態 A 都做不到。前者可以用內容優化解決,後者必須建立基礎實體(entity)才有資格優化。
1.3 為什麼這比 SEO 排名差更致命
| 比較維度 | 傳統 SEO 排名差 | AI Existence Gap |
|---|---|---|
| 你被「看見」的機會 | 排第 50 也會被找到 | 完全不會被提到 |
| 修復難度 | 改 SEO 兩週見效 | 需要 6-12 個月建實體 |
| 對手追上你的速度 | 對手做 SEO 也要時間 | 對手有 Wikidata 直接領先 |
| 用戶決策影響 | 用戶會看多家比較 | 用戶只看 AI 給的清單 |
| 商業損失計算 | 流失的點擊 | 流失的「進入考慮名單的權利」 |
傳統 SEO 時代,用戶會打開 Google,看到一頁 10 個結果。即使你排第 8、第 10,仍然有用戶會點。
AI 時代,用戶問 AI 一個問題,AI 給出 3-5 個選項。你不在那個清單裡,你連被比較的資格都沒有。更可怕的是:用戶不會懷疑這個清單是否完整。他們會假設「AI 已經幫我篩選過了」。
1.4 一個讓你冷靜下來的事實
讀到這裡,你可能會想立刻打開 ChatGPT 測試自己的品牌。請先冷靜,因為大部分人測試的方式是錯的。
最常見的錯誤是這樣測試:
「百原科技是什麼公司?」(直接輸入品牌名)
這是「已知品牌的事實查詢」(branded fact query)。即使 AI 完全不認識你,它仍可能用搜尋功能即時抓你的官網內容回答。這不能證明 AI 真的「認識」你。
正確的測試方式有三種:
測試 1:類別查詢(Category Query)
輸入你所屬的類別,看 AI 是否主動提到你:
- 「台灣有哪些精密機械加工廠?」
- 「推薦幾個台北的牙醫診所」
- 「亞洲的 GEO 服務商有哪些?」
如果 AI 的清單裡沒有你 → 這就是 Existence Gap。
測試 2:問題情境查詢(Problem Context Query)
模擬你的潛在客戶會問的問題:
- 「我的工廠需要找台灣的航太級鋁合金加工廠,有哪些選擇?」
- 「我牙齒有問題想找台北中山區的牙醫,有什麼推薦?」
- 「我們公司想做 GEO 優化,台灣有哪些供應商?」
測試 3:對比查詢(Comparison Query)
問 AI 比較你和競爭對手:
- 「將能數位 vs Welly SEO 哪個比較好?」
- 「百原科技 vs Tenten 哪個更適合 B2B 客戶?」
如果 AI 對你的競爭對手有完整描述,但對你含糊其辭甚至不提 → 這是 Recommendation Gap,比 Existence Gap 好一點,但仍嚴重。
做完這三個測試,你大概會發現:你過去花了大筆預算做的官網、SEO、社群行銷,在 AI 眼中幾乎沒有任何效果。這不是因為你做錯了什麼,是因為遊戲規則徹底改變了,而沒有人告訴你新規則是什麼。
1.5 規模上的恐怖數字
數字 1:80% 的品牌無法在 AI 中穩定出現
根據 AirOps 在 2025 年發表的大規模研究,只有 30% 的品牌能從一個 AI 答案維持到下一個答案,只有 20% 能在連續五次測試中維持出現。意思是:即使你今天測試 ChatGPT 提到了你的品牌,80% 的機率明天再測就消失了。
數字 2:12% 與 8% 的重疊率
根據 Ahrefs Brand Radar 對 15,000 個提示詞的研究:
- AI 引用與 Google top 10 結果的重疊率只有 12%
- ChatGPT 與 Google/Bing 的重疊率只有 8%
換句話說:就算你 SEO 排到 Google 第一頁,仍有 88% 的機率不會被 AI 引用。
數字 3:250 篇實質性文章的門檻
研究顯示,要在某個類別中有意義地改變 LLM 對品牌的認知,需要約 250 篇實質性文件。「實質性」的定義是:原創研究、清晰的作者署名、結構化資料、對該主題有真正深度的內容。不是業配文、不是 AI 生成的填充內容、不是新聞稿轉發。
數字 4:4.8 倍的實體權威加成
對 15,847 個 Google AI Overview 結果的分析顯示:在 Knowledge Graph 中有 15+ 連結實體的頁面,AI Overview 入選機率高 4.8 倍。而 Domain Authority(傳統 SEO 黃金指標)與 AI Overview 引用的相關係數,已從 2024 年的 0.23 降到 2026 年的 0.18——並且還在持續下降。
結論:傳統 SEO + 內容行銷的舊玩法,在 AI 時代效率極低。要在 AI 中被認識,需要完全不同的策略框架。這個框架,後面我會詳細介紹——它叫 MAEE。
第二章:8 篇國際論文揭露的真相
2.1 論文一:Princeton 的 GEO 開山之作
論文:GEO: Generative Engine Optimization(Aggarwal et al., Princeton / IIT Delhi, 2023, arXiv:2311.09735)。重要性 ★★★★★。
這篇論文第一次系統性提出「生成式引擎優化」的概念,建立 GEO-bench 跨領域基準測試,並系統性測試各種內容優化策略對 AI 引用率的影響。
三大最有效的內容優化策略:
| 策略 | 引用率提升 |
|---|---|
| 加入專家引述(Quote Addition) | +41% |
| 加入統計數據(Statistics Addition) | +30% |
| 加入內聯引用(Inline Citation) | +30% |
| 關鍵字堆砌(Keyword Stuffing) | −9% |
對台灣中小企業的意涵:如果你的官網內容沒有專家引述、沒有具體統計數據、沒有引用權威來源,你就是在讓 AI 主動忽略你。台灣中小企業的官網習慣寫「本公司提供高品質的精密機械加工服務,技術精湛,品質保證」——這種文案在 AI 眼中是零分。沒有具體事實,沒有數據,沒有引述。
2.2 論文二:Existence Gap 的官方學術定義
論文:Cultural Encoding in Large Language Models: The Existence Gap in AI-Mediated Brand Discovery(2026, arXiv:2601.00869)。重要性 ★★★★★。
論文的貢獻有三:
- 經驗證實「存在斷層」現象的真實性——LLM 訓練資料的地理分布會造成「隱形市場壁壘」。對台灣的意涵:你不只是「沒被 AI 認識」,你是「被 AI 訓練資料的地理偏見系統性排除」。
- 提出「Data Moat」(資料護城河)框架——主動製造大量、多元、連結的實體訊號,達成「演算法全在場」(Algorithmic Omnipresence)。
- 量化「存在斷層」的商業損失——在某些品類中,存在斷層導致的市場份額損失可能高達 40-60%。
當 AI 中介的決策比例越來越高(Gartner 預測 2026 年 Q4 會達到 60%),存在斷層的代價會持續放大。
2.3 論文三:AI 系統的 Earned Media 偏好
論文:Generative Engine Optimization: How to Dominate AI Search(Chen et al., 2025, arXiv:2509.08919)。重要性 ★★★★★。
AI Search 對 Earned Media(第三方權威來源)相對於 Brand-owned Sources(品牌自有來源)有系統性且壓倒性的偏好。
翻譯成商業語言:AI 不太信任你自己網站上說的話,但很信任別人說你的話。具體偏好:
- 第一層信任:政府機構、學術期刊、Wikipedia、Wikidata
- 第二層信任:知名媒體(Forbes、Reuters、紐約時報等)
- 第三層信任:行業協會、專業媒體、Reddit/Quora 等社群討論
- 第四層信任:同業評論、案例研究、第三方比較
- 最低層信任:品牌自己的官網、行銷文案、自製內容

對應的策略:主動建立 Wikipedia / Wikidata 條目、爭取媒體報導、加入行業協會、鼓勵客戶在 Google Maps 留下評論、提供案例研究、發表技術內容到 Medium / Substack / GitHub Pages。重點不是「自己誇自己」,是讓「別人有理由提到你」。
2.4 論文四:結構化內容工程的新視角
論文:Structural Feature Engineering for Generative Engine Optimization(Yu, Yang et al., 東京大學, 2026, arXiv:2603.29979)。重要性 ★★★★。
論文把內容結構分為三層:
- 宏觀結構(Macro-structure):清晰的章節層級(H1/H2/H3)、段落之間有邏輯連接、有摘要、結論、目錄等元素。
- 中觀結構(Meso-structure):列表、表格、定義框;段落長度適中(AI 偏好 50-150 字的段落);清晰的問答(Q&A)格式。
- 微觀結構(Micro-structure):粗體、斜體、底線;引用塊(blockquote);程式碼區塊;數字格式化(Stats 用 25% 比 25 percent 好)。
論文證明:即使語義內容完全相同,純粹改變結構就可以顯著影響 AI 引用率。
2.5 論文五:失敗診斷與自動修復
論文:Diagnosing and Repairing Citation Failures in Generative Engine Optimization(2026, arXiv:2603.09296)。重要性 ★★★★。
論文提出 GEO 失敗模式分類學(Failure Taxonomy),把 AI 不引用你的原因系統性分為五類:
- 檢索失敗(Retrieval Miss):你的內容根本沒進入 AI 的 top-k 檢索結果。
- 排序下降(Rerank Drop):進入了 top-k,但被 reranker 排到後面,最終沒被使用。
- 合成略過(Synthesis Skip):被檢索到、相關性也夠,但 LLM 在合成最終答案時略過你。
- 歸因失敗(Attribution Fail):內容被使用了,但 AI 沒明確標出來源是你。
- 跨平台漂移(Cross-Drift):不同 AI 平台對你的描述不一致,最終 AI 因「信號矛盾」而選擇略過。
論文提出 AgentGEO 框架——一個 agentic 系統,能自動診斷失敗模式。僅修改 5% 內容就達成 40% 相對引用率提升,遠超 baseline 的 25%。
2.6 論文六:Pinterest 的真實大規模案例
論文:Generative Engine Optimization: A VLM and Agent Framework for Pinterest Acquisition Growth(Pinterest + Stanford, 2026, arXiv:2602.02961)。重要性 ★★★★。
Pinterest 是第一家在學術論文中公開承認執行 GEO 戰略並公布實際成效的大廠。成果:20% 的 organic traffic 增長,貢獻數百萬月活用戶(MAU)增長。
2.7 論文七:Confidence Decay 與 Beyond RAG
論文:Beyond Retrieval: Modeling Confidence Decay and Deterministic Agentic Platforms in Generative Engine Optimization(2026, arXiv:2604.03656)。重要性 ★★★。
關鍵兩點:信心衰減(Confidence Decay)——LLM 對品牌資訊的「信心」會隨時間衰減;RAG 的商業侷限——本質上是機率性的、容易被 hallucinate、難以建立持續的商業信任。
正確的節奏感:
- 第 1-3 個月:建立基礎實體(脫離 Existence Gap)
- 第 4-6 個月:優化內容結構(提升引用率)
- 第 7-12 個月:累積第三方信號(建立 Earned Media)
- 持續:每月維護更新(對抗 Confidence Decay)
2.8 論文八:訓練資料注入的紅線討論
論文:Multi-Faceted Studies on Data Poisoning can Advance LLM Development(2025, arXiv:2502.14182)。重要性 ★★。
結論:理論上可以透過投放大量內容到網路上「污染」LLM 訓練,但實際操作極為困難。OpenAI、Anthropic、Google 都有強大的資料清理機制;中小規模的內容投放對最終模型影響微乎其微;一旦被識別為「人工 GEO 操控」,可能受到反向懲罰。
不要走偏門。正道才有複利。
第三章:為什麼台灣中小企業特別脆弱
3.1 訓練資料的地理偏見
| 語言 | 訓練資料佔比 |
|---|---|
| 英文 | 約 45-50% |
| 簡體中文 | 約 5-8% |
| 繁體中文 | 約 1-2% |
| 日文 | 約 2-3% |
| 韓文 | 約 1-2% |
| 其他 100+ 種語言 | 約 35-40% |

一家在英語世界營運的中型公司,被 ChatGPT 認識的機率,可能是同等規模台灣公司的 20-30 倍。這不是 OpenAI、Anthropic 故意歧視台灣,而是訓練資料的客觀分布造就的結構性偏見。
3.2 中小企業數量的稀釋效應
全台企業總數約 167 萬家,中小企業佔比約 98.5%。LLM 在「台灣」這個小池子裡,有 167 萬家企業可以被認識,但訓練資料量卻極為有限。對比美國(3,300 萬企業 + 英文 45-50% 佔比),「每家美國企業可分到的訓練資料量」比台灣多數十倍。
3.3 媒體生態的雙重結構問題
問題 A:B2B 報導極度稀缺——台灣媒體的注意力高度集中在政治、娛樂、大型上市公司、房地產。對中小型 B2B 企業的報導極度稀缺。一家年營收 4 億的精密機械廠,可能 10 年都沒有任何媒體報導。
問題 B:業配文化污染搜尋結果——AI 越來越能識別業配內容;業配累積的是低品質信號。很多台灣中小企業以為自己「做過很多媒體曝光」,但這些曝光在 AI 眼中幾乎沒有累積價值。
3.4 缺少 Wikidata / Wikipedia 認證的結構性壁壘
台灣中小企業 99% 以上沒有 Wikidata 條目。我用 Wikidata 公開 API 查證過台灣 GEO 服務業的領導品牌:
| 公司 | Wikidata Q-code |
|---|---|
| 將能數位 | 無 |
| Welly SEO | 無 |
| 零一行銷 | 無 |
| Tenten | 無 |
| Rankking | 無 |
| 戰國策集團 | 無(創辦人有條目,公司本身無) |
| Harris 先生 | 無 |
| 犬哥網站 | 無 |
整個產業沒有一家有自己的 Wikidata Q-code。這形成一個死循環:

3.5 數位行銷預算的結構性錯配
| 預算項目 | 舊模式比例 | 新模式建議 |
|---|---|---|
| Google Ads | 40% | 25% |
| Facebook/IG Ads | 30% | 15% |
| SEO | 20% | 15% |
| 內容資產建構(含 AXP) | 0% | 25% |
| 第三方權威信號建立 | 5% | 15% |
| AI 監測與優化(GEO) | 0% | 5% |
3.6 老闆認知的時間差
我們訪談 50 位台灣中小企業老闆,發現:能流暢使用 ChatGPT 的老闆約 30%;真正測試過自己品牌在 AI 中能見度的不到 5%;有 GEO 預算規劃的不到 1%。對比美國(60% / 15% / 5%)。這個 4-5 倍的認知差距,造就了未來 3-5 年的競爭真空。率先意識到、率先行動的台灣中小企業,將在 AI 時代享有結構性的領先優勢。
3.7 五大產業的 Existence Gap 實況
案例 1:醫療美學診所
對全台 30 家中型醫美診所做 AI 認知測試:在「台北醫美診所推薦」查詢中,30 家裡只有 3 家被 AI 提到;28 家的院長名字 AI 完全不認識;27 家有錯誤的療程定價資訊。一家年營收 5,000 萬的中型醫美診所,Existence Gap 直接造成的潛在客戶流失,估計每年 NT$ 500-800 萬。
案例 2:精密機械加工廠
對 25 家中型加工廠的測試:在「台灣 CNC 加工廠」、「五軸加工」等查詢中,0 家被 AI 主動提到。AI 給出的清單清一色是上市櫃大廠。B2B 採購者使用 AI 工具進行「初步供應商篩選」的比例已達 50%+。
案例 3:補教產業
對 40 家中型補習班的測試:區域型優質補教被提到的機率不到 15%;師資介紹、課程資訊常是錯的。Z 世代家長使用 AI 比例已達 60%。
案例 4:B2B SaaS 新創
對 20 家台灣 B2B SaaS 新創的測試:在「台灣 SaaS 工具推薦」查詢中,被提到的多是國際品牌(Notion、Slack、HubSpot);本土 SaaS 即使更符合台灣使用情境,仍經常被忽略;中型 B2B SaaS 幾乎不存在。
案例 5:傳統製造業(食品、紡織、家具)
對 20 家中型傳統製造商的測試:幾乎所有中型廠商都不存在於 AI 認知中;AI 列出的多是上市公司或極少數知名品牌。海外買家透過 AI 找供應商的比例已達 30-40%。
3.8 不同產業的 MAEE 優先順序差異
| 產業類型 | 第一優先層 | 第二優先層 |
|---|---|---|
| 醫療美學 | 第 1 層(衛福部許可) | 第 4 層(醫師個人品牌) |
| 精密機械 | 第 3 層(LinkedIn + 協會) | 第 4 層(技術內容) |
| 補教 | 第 4 層(師資內容) | 第 2 層(Google Maps) |
| B2B SaaS | 第 4 層(GitHub + Tech Blog) | 第 3 層(Crunchbase) |
| 傳統製造 | 第 3 層(國際 B2B 平台) | 第 4 層(多語內容) |
| 餐飲零售 | 第 2 層(地圖類) | 第 3 層(社群媒體) |
| 法律會計 | 第 4 層(專業內容) | 第 1 層(公會) |
第四章:Wikidata 為什麼不是答案
4.1 Wikidata 的硬性門檻
- Notability 標準:至少 2-3 篇獨立第三方可靠來源報導;不是行銷自我宣傳;有公共影響力證明。
- 可驗證性標準:每一個聲明都必須有獨立來源佐證。
- 中立性標準:條目必須以中立、百科全書式的語氣撰寫;不能用行銷語言;必須涵蓋負面資訊(如果有的話)。
- 編輯社群審核:提交條目後,由 Wikidata 全球志願編輯社群審核——可能被駁回(最常見)。
4.2 台灣中小企業的真實情況
照前述標準,99% 的台灣中小企業現在去申請 Wikidata 都會被駁回。而且駁回紀錄會留在 Wikidata 系統中。未來再申請會被標記為「曾被駁回」,重新通過的難度更高。這是個負面槓桿:操之過急反而傷害自己。
4.3 條件夠的少數企業
- 條件 A:媒體報導豐富——至少 3 篇獨立記者撰寫的報導(非業配)。
- 條件 B:上市櫃公司或準上市櫃——有公開財務報告、有獨立分析師研究報告。
- 條件 C:有獎項或政府認證——國家品牌玉山獎、磐石獎;經濟部、數位發展部等中央級政府認證。
- 條件 D:有重大公共影響力——業務涉及社會重要議題;創辦人有獨立的公共名聲。
4.4 不該追 Wikidata 的判斷邏輯
如果你不符合,追 Wikidata 是錯誤的優先順序。正確的順序:
階段 1(M1-M3):建立次級錨點
↓
階段 2(M4-M9):累積第三方信號
↓
階段 3(M9-M12):條件成熟後申請 Wikidata4.5 一個誠實的承認
寫這一章之前,我必須誠實地告訴你:百原科技自己也沒有 Wikidata Q-code。我們現在的計畫是:
- M1-M3:完成 Google Business Profile、LinkedIn、Crunchbase 等次級錨點
- M3-M6:投稿技術內容到 iThome、INSIDE 等媒體
- M6-M9:開源 GEO-Bench-Taiwan 資料集,建立學術連結
- M9-M12:累積足夠的獨立來源後,提交 Wikidata 條目
12 個月後,我們希望成為台灣第一家擁有自己 Wikidata Q-code 的 GEO 服務商。我們相信「先把自己做給客戶看」比「只賣理論給客戶」更有意義。
第五章:MAEE 框架——台灣中小企業的 AI 護城河
5.1 MAEE 是什麼
MAEE 是 Multi-Anchor Entity Establishment 的縮寫,翻譯成中文是「多錨點實體建立框架」。
既然 Wikidata 這個「單點權威」走不通,那就建立多個「次級權威來源」,讓 AI 透過「多點交叉驗證」認識你。
AI 識別實體的機制,本質上是「訊號交叉驗證」(signal cross-validation)。當「某個品牌名」與「統一編號」、「Google Place ID」、「LinkedIn URL」、「商標號碼」在多個獨立來源中反覆共同出現時,AI 會在向量空間中將這些訊號聚合,形成「這是一個真實實體」的判斷。
5.2 MAEE 的五層錨點結構

第 1 層:政府與法人錨點(地基)
- 經濟部商業司公司登記
- 智慧財產局商標註冊
- 衛福部許可項目(醫療相關)
- 金管會證券資訊(如為公開發行)
- 各部會核准、許可、認證
第 2 層:地理與營運錨點(座標)
- Google Business Profile
- Apple Business Connect / Apple Maps
- Bing Places for Business
- Foursquare、Yelp(國際版)
- 行業特定地圖(醫美、餐飲等)
第 3 層:商業關係錨點(連結)
- LinkedIn Company Page(這層最重要)
- Crunchbase
- LINE Official Account(台灣特有)
- 104 / 1111 公司頁面、CakeResume
- 業界協會會員資料、商會資料
第 4 層:媒體與內容錨點(背書)
- 自有部落格(強烈推薦)
- Medium / Substack(國際 AI 信任度高)
- GitHub Pages(技術型品牌極佳)
- YouTube 頻道、Podcast 來賓紀錄
第 5 層:跨平台 sameAs 鏈(黏合劑)
這層不是新增錨點,而是讓上述 1-4 層「合而為一」。每個錨點的 schema.org JSON-LD 都用 sameAs 屬性互相指向,形成閉合的實體網:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "你的公司名",
"identifier": [
{"@type": "PropertyValue", "propertyID": "tw_business_id", "value": "你的統編"},
{"@type": "PropertyValue", "propertyID": "google_place_id", "value": "你的 Google ID"}
],
"sameAs": [
"https://www.linkedin.com/company/你的slug",
"https://www.crunchbase.com/organization/你的slug",
"https://www.facebook.com/你的slug",
"https://www.youtube.com/@你的slug",
"https://github.com/你的slug",
"https://medium.com/@你的slug",
"https://line.me/R/ti/p/@你的lineid",
"https://g.page/你的GoogleBusinessID",
"https://www.104.com.tw/company/你的id"
]
}5.3 五層錨點的權威階層

| 階層 | 錨點類型 | AI 採信權重 | 中小企業可達成性 |
|---|---|---|---|
| S 級(最高) | Wikidata + Wikipedia | 極高 | 1% |
| A 級 | Crunchbase 完整版 + LinkedIn 已認證 | 高 | 30% |
| B 級 | Google Business Profile + 政府登記 + 行業協會 | 中高 | 80% |
| C 級 | 自有官網結構化資料 + 多平台 sameAs 互鏈 | 中 | 100% |
| D 級 | 第三方目錄站、評論平台、社群媒體 | 低中 | 100% |
當 S 級不可達時,組合 A+B+C+D 級錨點,可以堆疊出接近 S 級的 AI 識別效果。Authority Tech 的研究:「Wikidata + Wikipedia + 4 個以上第三方平台的品牌,AI 引用次數是沒有經過驗證實體狀態品牌的 2.8 倍」。
5.4 MAEE 對抗 Existence Gap 的數學模型
假設一個品牌「被 AI 認識」的機率為 P:
P = 1 − ∏(1 − P_i)單一錨點(只有官網,P_1 = 0.05)→ P = 0.05。建立 7 個錨點 + sameAs 鏈:P ≈ 0.49。從 5% 提升到 49%,是 9.8 倍的提升。

5.5 為什麼這個方法對台灣中小企業特別有效
- 不依賴媒體報導——MAEE 從自己掌握的錨點開始建立,不需要等媒體。
- 成本低、速度快——B 級錨點一週內可完成。
- 可累積、不可逆——錨點是永久資產。
- 與既有資產相容——既有的 Facebook、LINE、官網、Google 評論都可整合。
- 對抗對手簡單——對手知道你在用 MAEE,也需要 6-12 個月才能追上。
5.6 MAEE 與其他 GEO 方法論的比較
| 維度 | 傳統 SEO 升級版 | 內容軍備競賽 | 黑帽 GEO | MAEE |
|---|---|---|---|---|
| 目標客戶 | 已有 AI 認知的品牌 | 大型企業 | 不擇手段者 | 中小企業 |
| 起步成本 | 中(10-30 萬) | 高(100 萬+) | 低 | 低(10-25 萬) |
| 起效時間 | 3-6 個月 | 12-18 個月 | 1-2 個月(短期) | 3-6 個月(穩定) |
| 長期 ROI | 中 | 高 | 負(會被懲罰) | 高 |
| 風險 | 低 | 中 | 極高 | 低 |
| 適合台灣中小企業 | 部分 | 不適合 | 不適合 | 完美匹配 |
5.7 MAEE 對你 5 年後的意涵
5 年後(2031 年)的市場情境預測:AI 中介決策比例達 75-85%;沒有 AI 認知的品牌基本被市場淘汰;Wikidata 成為標配,中小企業擁有 Q-code 比例從 1% 上升到 20-30%。
台灣的 B2B SaaS 圈,2024 年開始認真做 GEO 的公司,到 2026 年的市占率與業績,普遍領先同期未啟動的競爭對手 30-50%。MAEE 不是「錦上添花」,是「生存必需」。
第六章:五層錨點實作指南
6.1 第 1 層:政府與法人錨點實作
6.1.1 經濟部商業司資料同步
前往 findbiz.nat.gov.tw,確認公司名稱(中英文)、統一編號、負責人姓名、公司地址、設立日期、資本總額、營業項目代碼,並結構化整合進 schema.org JSON-LD:
"identifier": [
{
"@type": "PropertyValue",
"propertyID": "tw_business_id",
"value": "你的8位數統編"
},
{
"@type": "PropertyValue",
"propertyID": "tw_legal_name",
"value": "你的公司全名(含「有限公司」等字樣)"
}
]常見問題:很多中小企業老闆不知道自己網站上的公司名稱跟商業司登記不完全一致。這在 AI 眼中是不一致的訊號。
6.1.2 智慧財產局商標登錄
前往 twtmsearch.tipo.gov.tw,記錄商標號、註冊日期、指定商品類別,加入 schema.org。
6.1.3 衛福部許可(如適用)
給醫療美學、保健食品、化妝品業者:衛福部許可項目編號、TFDA 化妝品 PIF 認證資訊、HACCP / ISO 22000 等食品安全認證——加入 schema.org additionalType 欄位。
6.2 第 2 層:地理與營運錨點實作
6.2.1 Google Business Profile(最優先)
前往 business.google.com,用部門信箱(不是個人信箱)建立。填寫的關鍵原則:
- Description 寫滿 750 字:包含成立年份、核心業務、服務區域、認證、客戶類型
- 上傳 5-10 張高品質照片:辦公室、團隊、產品、服務情境
- 設定服務區域;加入 5-10 個 Q&A
完成後立刻:把 Google Business Profile URL 加進 schema.org sameAs;邀請現有客戶留下 Google Maps 評論。
6.2.2 Apple Business Connect
用部門信箱建立 Apple ID,前往 businessconnect.apple.com。台灣商家容易踩的雷:Apple ID 一定要用部門信箱;地址用繁體中文,不寫郵遞區號;Category 沒有「GEO 服務」對應選項,建議選「Marketing Agency」+「IT Services」。
6.2.3 其他地圖類錨點
| 平台 | 重要性 | 註冊難度 | 預估時間 |
|---|---|---|---|
| Bing Places for Business | 中 | 低 | 30 分鐘 |
| Foursquare for Business | 中 | 低 | 20 分鐘 |
| Yelp for Business(國際) | 中 | 低 | 30 分鐘 |
| 行業特定地圖 | 高(按行業) | 中 | 1-2 小時 |
6.3 第 3 層:商業關係錨點實作
6.3.1 LinkedIn Company Page(B2B 必做)
這是 MAEE 第 3 層中最重要的錨點。LinkedIn 對英文 AI(ChatGPT、Claude、Perplexity)的權威性極高,且資料結構非常完整。
About 區結構建議(目標 2000 字):
- 公司一句話定位(25 字內)
- 核心業務介紹(200 字):解決什麼問題、服務什麼客戶、主要產品或服務
- 公司歷史與里程碑(300 字):成立年份、重要事件、客戶數、員工數等可驗證數據
- 技術或方法論優勢(500 字):與競爭對手的差異、引用具體技術名詞、引用研究或標準
- 客戶案例摘要(300 字):服務過的客戶類型、達成的具體成果、數據佐證
- 認證、獎項、合作夥伴(200 字)
- 聯絡資訊與行動呼籲(100 字)
員工關聯極其重要:確保所有員工的個人 LinkedIn 都正確標註雇主。每個員工就是一個對外的 AI 信號錨點。
6.3.2 Crunchbase 條目建立
前往 crunchbase.com,點擊 "Add a Company",填寫公司名稱(英文為主)、成立日期、總部地址、員工數、公司描述(300-500 字)、創辦人/CEO、主要產品。連結 LinkedIn、官網、Twitter,等待審核(通常 1-2 週)。
6.3.3 LINE Official Account(台灣特有)
LINE OA 對台灣 AI 系統權威性極高。完成後把 LINE OA URL 加進 schema.org sameAs。
6.3.4 人力銀行公司頁
| 平台 | 對 AI 的重要性 |
|---|---|
| 104 公司頁 | 高(中文 AI 高頻抓取) |
| CakeResume | 高(國際曝光好) |
| 1111 | 中(傳統產業搜尋) |
| Yourator | 中(新創導向) |
6.3.5 業界協會會員身份
這是被嚴重低估的錨點。年費 NT$ 5,000-30,000,但建立的是長期不可逆的權威信號。
6.4 第 4 層:媒體與內容錨點實作
6.4.1 自有部落格啟動
在你公司主網域下建立 /blog 子目錄(強烈不建議用 medium.com 等外站當主部落格)。每月至少 4 篇實質性文章;每篇 1500 字以上;包含具體數據、引述、案例;結構化呈現。
6.4.2 Medium / Substack
每月 1-2 篇,與自有部落格的最佳內容雙語同步發布。
6.4.3 GitHub Pages(技術型品牌)
百原科技的 RAG 白皮書就是放在 baiyuan-tech.github.io/rag-whitepaper/——這個錨點對我們的國際 AI 認知建立有顯著貢獻。
6.4.4 YouTube 頻道
即使影片觀看量不高,頻道存在本身就是 AI 信號。
6.4.5 Podcast 露出
主動爭取上其他人的 podcast 當來賓——一次錄音可以同時建立多個錨點(podcast 平台、主持人網站、文字稿頁面)。每季至少上 1-2 個產業相關 podcast。
6.5 第 5 層:sameAs 黏合鏈實作
完成 1-4 層的所有錨點後,回到官網,更新 schema.org JSON-LD 的 sameAs 屬性。完整範本:
{
"@context": "https://schema.org",
"@type": "Organization",
"@id": "https://你的網域.com/#organization",
"name": "你的公司全名",
"alternateName": ["公司簡稱", "英文名稱"],
"legalName": "你的公司全名(含有限公司等字樣)",
"url": "https://你的網域.com",
"logo": {
"@type": "ImageObject",
"url": "https://你的網域.com/logo.png",
"width": 500,
"height": 500
},
"foundingDate": "你的成立日期 YYYY-MM-DD",
"address": {
"@type": "PostalAddress",
"streetAddress": "你的街道地址",
"addressLocality": "你的鄉鎮市區",
"addressRegion": "你的縣市",
"postalCode": "你的郵遞區號",
"addressCountry": "TW"
},
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+886-X-XXXXXXXX",
"email": "info@你的網域.com",
"contactType": "Customer Service",
"availableLanguage": ["zh-TW", "en"]
},
"identifier": [
{
"@type": "PropertyValue",
"propertyID": "tw_business_id",
"value": "你的統編"
}
],
"sameAs": [
"https://www.linkedin.com/company/你的slug",
"https://www.crunchbase.com/organization/你的slug",
"https://www.facebook.com/你的slug",
"https://www.instagram.com/你的slug/",
"https://www.youtube.com/@你的slug",
"https://github.com/你的slug",
"https://medium.com/@你的slug",
"https://line.me/R/ti/p/@你的lineid",
"https://g.page/你的GoogleBusinessID",
"https://www.104.com.tw/company/你的id",
"https://www.cakeresume.com/companies/你的slug"
]
}用 Google Rich Results Test 與 Schema.org Validator 驗證。
第七章:90 天落地路線圖
7.1 整體節奏

Week 1-2:基礎建設(修正既有資產)
Week 3-4:第 2 層地理錨點(Google Business Profile + Apple)
Week 5-6:第 3 層商業關係錨點(LinkedIn + Crunchbase)
Week 7-8:第 4 層內容錨點啟動(部落格 + Medium)
Week 9-10:媒體投稿與協會申請
Week 11-12:sameAs 整合 + 90 天成果驗收7.2 Week-by-Week 詳細計畫
Week 1:基礎資料盤點與修正
- 確認商業司登記資料是否最新
- 盤點所有現有對外平台的公司資料
- 列出所有不一致的地方(地址、電話、Email、負責人、成立年份)
- 建立「標準資料表」作為後續所有錨點的填寫依據
Week 2:官網 schema.org JSON-LD 完整實作
- 在官網
<head>加入完整 Organization schema - 用 Google Rich Results Test 驗證
- 提交 sitemap 到 Google Search Console / Bing Webmaster Tools
Week 3:Google Business Profile 註冊與驗證
Week 4:Apple Business Connect 註冊(並行 Bing Places、Foursquare)
Week 5:LinkedIn Company Page 完整建立
確保所有員工正確標註雇主;每週至少 2 篇 LinkedIn 貼文。
Week 6:Crunchbase + 104 + CakeResume + LINE OA
Week 7:自有部落格啟動
Week 8:Medium / Substack / GitHub Pages / YouTube 頻道
Week 9:第一篇技術投稿
這是 90 天計畫中商業價值最高的單一動作。投稿目標:iThome / INSIDE / TechOrange / Search Engine Land。撰寫 3000-5000 字技術文章。
Week 10:業界協會申請
Week 11:完整 sameAs 整合(MAEE 的「收割時刻」)
Week 12:90 天成果驗收
重新執行第一章的「三種測試方式」,比較 90 天前後的差異;對 6 大 AI 平台(ChatGPT、Claude、Gemini、Perplexity、DeepSeek、Grok)逐一測試。
7.3 預期成果
| 指標 | Day 0 | Day 90 預期 |
|---|---|---|
| Google Business Profile 完整度 | 0% | 100% |
| LinkedIn Company Page 完整度 | 0-30% | 95%+ |
| schema.org sameAs 連結數 | 1-3 | 10+ |
| 自有部落格文章數 | 0 | 8-12 |
| Medium 文章數 | 0 | 4-8 |
| 業界協會會員身份 | 0 | 1-3 個 |
| 媒體報導數 | 0 | 1-2 篇 |
注意:90 天還不足以完全跨越 Existence Gap。AI 訓練資料更新有滯後性,部分變化可能要 6-12 個月才完全顯現。
7.4 持續維護的節奏
- 每週:部落格 1-2 篇;LinkedIn 2-3 篇貼文;監測 AI 平台的品牌提及變化
- 每月:1 篇外部投稿;1 個新的內容據點;更新 Google Business Profile
- 每季:申請新的業界協會;評估是否申請新獎項;重新測試 AI 認知狀態
- 每年:評估是否有資格申請 Wikidata;重新規劃 schema.org 結構
7.5 預算建議
最低預算(DIY 版):NT$ 91,000——業界協會年費 30,000、部落格平台年費 6,000、商業司印鑑變更 5,000、內容委外 30,000、工具訂閱 20,000。
標準預算(半委外版):NT$ 250,000——內容代筆 80,000、設計 30,000、媒體投稿協助 30,000、GEO 監測平台 60,000、其他 50,000。
完整預算(全委外版):NT$ 750,000——GEO 顧問服務(季費)300,000、內容代筆 200,000、媒體公關 150,000、平台訂閱 100,000。
對比參考點:台灣中小企業每年 Google Ads + Facebook Ads 平均預算約 NT$ 50-300 萬。從這個預算挪出 5-15% 投入 MAEE,長期 ROI 遠高於繼續加碼舊渠道。
第八章:常見的五個誤區
8.1 誤區一:以為「做 SEO 就等於做 GEO」
| 維度 | SEO | GEO |
|---|---|---|
| 優化目標 | 排名(ranking) | 引用(citation) |
| 衡量單位 | 流量(traffic) | 提及(mention) |
| 主要訊號 | 反向連結(backlinks) | 實體權威(entity authority) |
| 內容偏好 | 關鍵字相關 | 結構化、可引用 |
| 第三方角色 | 連結交換 | 獨立背書 |
| 成功標準 | 第 1 頁 | 進入答案清單 |
SEO 排第 50 的網站還能被找到。GEO 沒進答案清單就是不存在。
8.2 誤區二:以為「做一次就好」
LLM 對品牌資訊的「信心」會隨時間衰減。如果你做完 90 天 MAEE 計畫就停下來,12 個月後你會回到接近起點的狀態。GEO 是「長跑」,不是「衝刺」。
8.3 誤區三:追求「快速效果」走偏門
市場上常見的「黑帽 GEO」手法:大量發布業配文到第三方平台、偽造專家引述/虛假統計數據、操作虛假 Google 評論、建立「人偶網站」互相引用、參加付費「業界排名」。
為什麼危險:
- AI 平台的反制機制持續進化,一旦被識別為「不自然優化」,會受到系統性懲罰。
- 學術界正在把灰色操作列為攻擊面(2025 年 12 月 position paper《On the Risks of Generative Engine Optimization in the Era of LLMs》)。
- 在 YMYL 領域涉及法律風險(公平交易法、消費者保護法、醫師法、藥事法、衛福部 PIF 規範)。
- 競爭對手會反向利用——把證據截圖送到 AI 平台檢舉。
8.4 誤區四:低估自有錨點的價值
正確順序:先把自有錨點做完整(schema.org、官網結構、自有部落格)→ 再建立平台錨點(GBP、LinkedIn、Crunchbase)→ 最後追求外部背書(媒體、協會、Wikidata)。
8.5 誤區五:忽視跨平台一致性
常見的不一致狀況:公司名稱不一致(商業司是「百原科技有限公司」,但 LinkedIn 寫「百原科技」,Crunchbase 寫「Baiyuan Technology」);地址、電話、成立年份、負責人不一致。當 AI 看到不同平台對同一品牌有不同描述時,它會降低對該品牌的整體信任度,甚至選擇略過該品牌。
避免方法:建立「黃金主檔」(Master Record);每季跨平台稽核;變更時的標準作業流程;使用 GEO 監測工具。
第九章:結語——你的品牌值得被 AI 看見
9.1 一個 28 年精密機械廠老闆的後續故事
文章開頭那位台中精密機械廠的老闆,後來怎麼樣了?他做了三件事:開始閱讀;成立內部「AI 能見度小組」;啟動 90 天計畫。
90 天後:Google Business Profile 100%;LinkedIn 累積 23 篇貼文;Crunchbase 通過審核;在工商時報發表了一篇技術專欄;加入區域同業公會與中華精密機械工業同業公會;自有部落格累積 11 篇技術文章。
180 天後(目前進度):在 ChatGPT 問「台灣有哪些值得推薦的中小型 CNC 加工廠」時,他的公司開始出現在前 10 名清單中;收到第一封來自德國買家的詢價信,買家明確表示「ChatGPT 推薦了你們」;累積 4 篇媒體報導;開始準備 Wikidata 條目申請。

「我做了 28 年精密機械,從來沒想過自己有一天會花時間研究『怎麼讓 AI 認識我』。但這 6 個月學到的東西,可能比過去 5 年加起來還多。」
9.2 一個簡單的選擇題
選擇 A:什麼都不做——3-5 年內,你的品牌會逐步從 AI 認知中淡出。
選擇 B:開始建立 MAEE——12 個月後你會擁有完整的數位實體身份、比 99% 同業更強的 AI 認知度、累積中的內容資產、結構性的競爭優勢。
選擇 C:等等看再說——失去先發優勢的時間視窗。
選擇 B 是唯一理性的選項——即使最終 AI 時代發展跟預期不同,MAEE 框架的所有錨點仍然是有商業價值的數位資產。
9.3 為什麼這個時間點是關鍵
現在(2026 年 4 月)的市場狀態:AI 中介決策比例約 35-45%;Gartner 預測 2026 年 Q4 將達到 60%;台灣中小企業有 GEO 概念的不到 5%;真正執行 GEO 的不到 1%。
你現在啟動 MAEE 的優勢:你在最早的 1% 之中;你有 12-18 個月的「先發紅利期」;等大部分對手開始做時,你已經建好護城河。這跟 2010 年代開始做 SEO 的時間視窗是一樣的。
9.4 給每一種讀者的具體下一步
如果你是企業主或創辦人:下週做這件事——找一個 30 分鐘的時間,自己用 ChatGPT、Claude、Perplexity 各做一次「類別查詢」測試。把結果截圖,拿給你的行銷主管。
如果你是行銷主管或 CMO:把這篇文章轉發給你的老闆,附上一句話:「這是我們明年數位行銷預算需要重新規劃的依據。」
如果你是數位轉型負責人:把本文當作工作筆記。每章對應一個工作項目。建立公司內部的「MAEE 推進儀表板」。可以先聯繫我們做免費的 60 秒能見度健檢:geo.baiyuan.io/diagnose。
9.5 百原科技的承諾
- 我們研究的論文,會公開分享。
- MAEE 框架的方法論,會持續開源(CC BY-NC 4.0)。
- 我們自己會走這條路——百原科技目前也在執行自己的 90 天 MAEE 計畫。
- 我們不做黑帽 GEO——不做訓練資料注入、不做虛假評論操作、不做業配文掩護。
- 我們相信長期主義——所有服務、方法論、工具,都是設計來陪客戶走 12-36 個月的長期合作。
9.6 最後一句話
寫這篇文章花了我們團隊整整 3 週時間。讀完它花了你約 60 分鐘。執行它,會花你的公司 12 個月。但這 12 個月會決定你的品牌,在未來 10 年的 AI 時代是「存在」還是「不存在」。選擇權在你手上。
附錄:常見問題快問快答
Q1:MAEE 跟傳統 SEO 衝突嗎?我還要繼續做 SEO 嗎?
不衝突,要繼續做。MAEE 是 SEO 的延伸,不是取代。只做 SEO 不做 MAEE 是失衡的——你會在 Google 排名好,但在 AI 中隱形。
Q2:我公司已經 30 年了,還來得及做 MAEE 嗎?
絕對來得及,且 30 年的歷史是你的優勢。30 年累積的客戶關係、產品數據、案例故事,都是 MAEE 第 4 層的內容素材。
Q3:我是個人品牌(律師、會計師、顧問),MAEE 適用嗎?
完全適用。個人品牌不需要 schema.org Organization,改用 Person schema。錨點清單調整為:LinkedIn 個人頁、Google Scholar、SSRN、Medium、自有部落格、業界協會、執業證照公開查詢等。
Q4:MAEE 90 天計畫,我公司沒人手執行怎麼辦?
三個選項:(1) 內部找一個對 AI 有興趣的員工兼任「GEO 負責人」,每週 5-10 小時;(2) 外包給 GEO 服務商;(3) 老闆每天投入 30-60 分鐘親自執行。
Q5:MAEE 的 ROI 怎麼衡量?
短期(3-6 個月):AI 認知改善、第三方錨點完整度。中期(6-12 個月):AI 引導流量、AI 引導詢價、媒體報導累積。長期(12-36 個月):市占率、業績、客戶取得成本下降。
Q6:我的競爭對手已經在做 MAEE 了,我還有機會嗎?
仍然有機會,但時間窗口縮小了。馬上啟動。每延遲 1 個月,追趕成本上升 10-15%。台灣中小企業真正執行 MAEE 的不到 1%,99% 的市場仍是空白。
Q7:AI 平台會不會反制 MAEE 這類優化策略?
不會反制白帽 MAEE。AI 平台反制的是操控、虛假、欺詐性的優化。MAEE 做的是「讓真實的你被準確認知」,這跟 AI 平台的利益一致。
Q8:MAEE 框架是專利嗎?我可以自己用嗎?
MAEE 框架的核心方法論公開,採用 Creative Commons BY-NC 4.0 授權。你可以自由使用、改編、傳播,唯一要求是非商業性使用且註明出處。
Q9:百原科技的 GEO Platform 跟 MAEE 框架是什麼關係?
MAEE 是方法論,GEO Platform 是工具。沒有工具也能執行 MAEE。但工具能讓執行效率提升 5-10 倍:自動監測 AI 認知變化、自動產生 schema.org、跨平台一致性檢查、AI 引用率追蹤等。
Q10:如果讀完這篇文章只能做一件事,該做什麼?
去你公司的官網,檢查是否有完整的 schema.org JSON-LD。如果沒有,請工程師加上去。這是 30 分鐘可以完成、立即見效、零風險的第一步。從這裡開始,慢慢往下走。
延伸閱讀
核心學術論文:
- Aggarwal, P. et al. (2023). GEO: Generative Engine Optimization. arXiv:2311.09735
- (2026). Cultural Encoding in Large Language Models: The Existence Gap in AI-Mediated Brand Discovery. arXiv:2601.00869
- Chen, M. et al. (2025). Generative Engine Optimization: How to Dominate AI Search. arXiv:2509.08919
- Yu, J. et al. (2026). Structural Feature Engineering for Generative Engine Optimization. arXiv:2603.29979
- (2026). Diagnosing and Repairing Citation Failures in Generative Engine Optimization. arXiv:2603.09296
- Zhang, F. et al. (2026). GEO: A VLM and Agent Framework for Pinterest Acquisition Growth. arXiv:2602.02961
- (2026). Beyond Retrieval: Modeling Confidence Decay and Deterministic Agentic Platforms. arXiv:2604.03656
- (2025). Multi-Faceted Studies on Data Poisoning can Advance LLM Development. arXiv:2502.14182
百原科技資源:
本文由百原科技有限公司(Baiyuan Technology)GEO 研究團隊撰寫,整合 8 篇國際學術論文研究、200+ 家台灣企業諮詢經驗,以及百原 GEO 平台的內部資料。本文採用 Creative Commons BY-NC 4.0 授權;允許非商業性轉載,但需標明出處與作者。商業性使用請聯絡百原科技。了解更多:geo.baiyuan.io