一個兩週前才出現的名詞,為什麼你應該關心
2026 年 4 月 4 日,Andrej Karpathy 在 GitHub Gist 上發表了一篇看起來很低調的技術筆記,標題只有三個字:LLM Wiki。
如果你不認識 Karpathy,簡單說明:他是 OpenAI 創辦團隊的核心成員、Tesla 前 AI 總監,在 AI 技術圈有近乎宗師級的影響力。這篇 Gist 發表不到兩週,就累積超過 5,000 個 star、4,400 個 fork,GitHub、Medium、Zenn、Qiita、日本韓國的技術圈全部瘋傳。各家大廠的 AI 工程師,都在討論這個「可能是比 RAG 更好的新架構」。
這篇文章想告訴企業決策者三件事:
第一,LLM Wiki 不只是技術話題,它背後的商業邏輯叫「知識複利」,可能是接下來 5 年決定企業 AI 投資報酬率的核心概念。
第二,Karpathy 提出的是「架構想法」,不是可以直接買來用的產品,他自己都在 Gist 裡說「這是想法不是實作」。
第三,百原科技在 rag.baiyuan.io 推出的 LLM Wiki + RAG 雙層知識引擎,是目前市場上最完整呼應這個架構的 SaaS 產品 — 而且解決了 Karpathy 原始架構的幾個關鍵缺陷。
如果你是企業 CEO、行銷長、或 AI 轉型的推動者,接下來的內容值得細讀。因為這不只是技術選型問題,而是你公司未來每年花出去的 AI 預算,是在「燒錢」還是在「投資」。
第一部分:為什麼 AI 投資很容易變成「折舊」而非「複利」
先講一個台灣企業常見的場景。
某家中型專業服務公司,過去五年累積了大量專業知識:客戶案例報告、產業分析、內部培訓教材、客服問答紀錄、產品規格文件、法遵指南。保守估計超過 10,000 份文件,這是公司最值錢的智慧資產之一。
2024 年,公司開始導入 AI 工具 — 給員工用 ChatGPT Enterprise、接 Copilot、甚至上了一個 RAG 系統把內部文件餵給 AI。一年過去,內部使用率有了,但有兩件事變得很尷尬:
第一件尷尬的事:當員工問 AI「我們公司過去三年最成功的醫療業客戶案例是什麼?可以幫我整理成提案用的 case study 嗎?」AI 確實會根據上傳的文件回答,但每次回答都從零開始,像是新來的實習生第一天讀所有檔案。它找到幾個相關段落、拼湊出答案,然後答案就消失在對話紀錄裡,下一次有人問類似問題,AI 還是從頭再來一次。
第二件尷尬的事:這家公司用 AI 這一整年,累積了無數次高品質的問答 — 員工用 AI 整理資料、解釋複雜條款、對比產品差異、總結會議重點。但當員工離開公司、專案結束、或 AI 對話被刪除,所有這些智慧累積瞬間歸零。公司付費使用 AI,得到的是一次性的答案,而不是可累積的資產。
這就是 Karpathy 在 LLM Wiki 提案中,一針見血指出的問題:傳統 RAG 讓 LLM 在每次查詢時重新發現知識,沒有任何累積。你的 AI 用得再久、問得再頻繁,知識沒有複利,只有折舊。
知識複利的商業意義
「複利」這個詞來自金融 — 愛因斯坦說過人類最偉大的發明是複利。把這個概念套用到企業知識管理,意思是:
每一次 AI 被使用,都應該讓整個知識庫變得更好,而不是只產出一個用完即丟的答案。
這件事做好與做壞的差異,3 年後會非常驚人:
- 做壞的公司:每年投入 X 元在 AI,每年產出的知識價值 = X 元(持平折舊)
- 做好的公司:每年投入 X 元在 AI,知識資產累積成 1.3X、1.7X、2.2X...(指數成長)
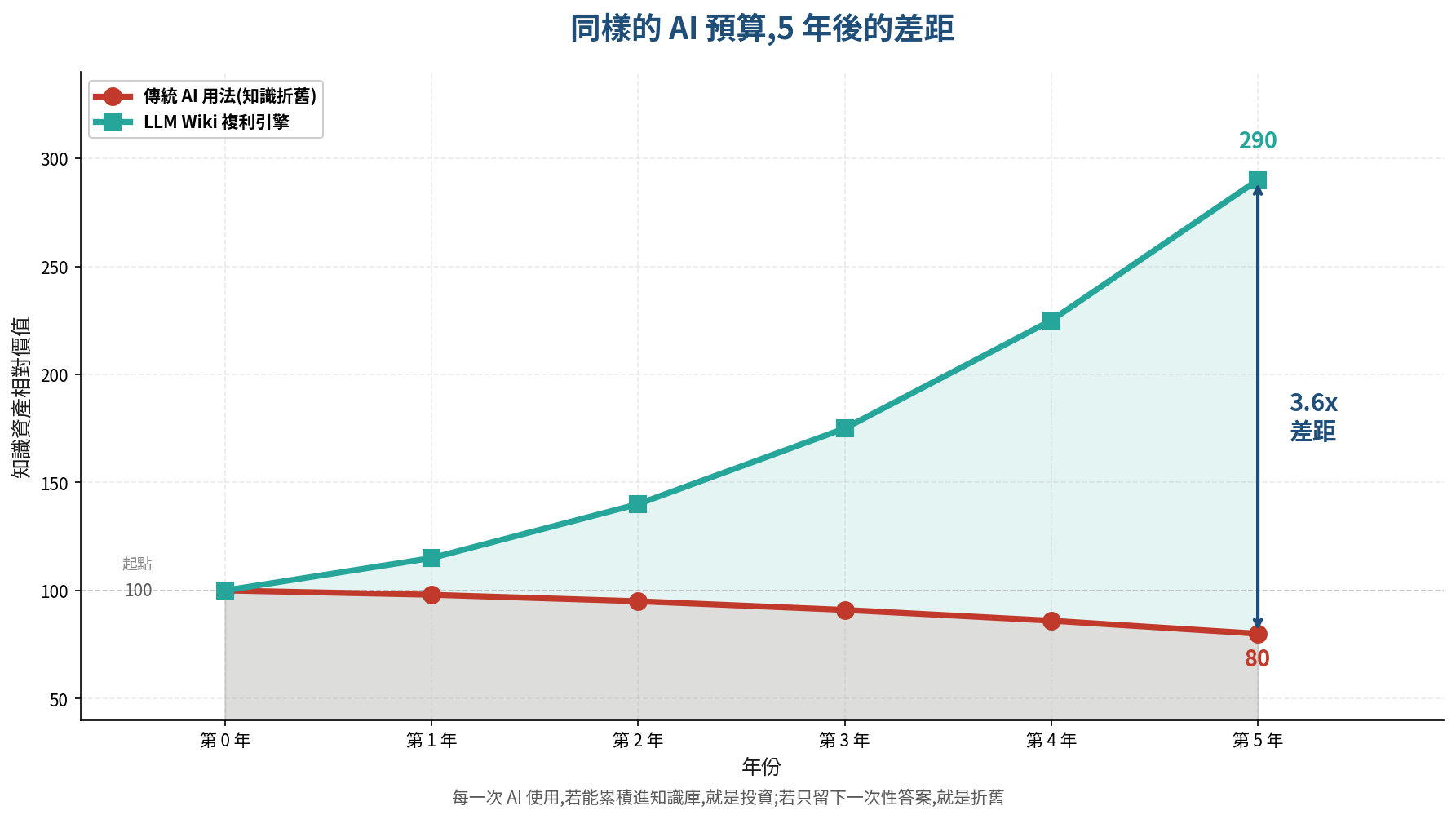
同樣的預算,一邊在折舊,一邊在複利。這才是為什麼 CEO 應該認真看待 LLM Wiki 這個概念,而不是把它當成工程師的技術玩具。
第二部分:Karpathy 的 LLM Wiki 架構在說什麼
Karpathy 的原始提案,核心只有一個動作:不要讓 LLM 每次從 raw 文件去檢索答案,而是讓 LLM 先把 raw 文件「編譯」成一個持續成長、相互連結的結構化知識庫 — 這個知識庫就叫 LLM Wiki。
他把架構拆成三層:
第一層:Raw Sources(原始資料層) — 不可變的原始文件,像是公司的年報、合約、客戶會議紀錄、產品規格、客服對話紀錄等。這一層是事實來源,LLM 只讀不寫。
第二層:Wiki(知識層) — LLM 把 raw sources 讀進來之後,編譯出來的結構化 Markdown 文件。每個重要概念、實體、主題都有獨立的頁面,頁面之間有 Wiki-style 的雙向連結,整個 Wiki 形成一張知識圖。這一層由 LLM 自己維護 — 當有新 raw source 進來,LLM 不只是把它索引存起來等下次檢索,而是讀懂後整合進現有 Wiki,可能更新 10-15 個相關頁面、補充新連結、標註和舊資料的衝突。
第三層:Schema(規範層) — 一份告訴 LLM「這個 Wiki 怎麼組織、有哪些規則、每種頁面該怎麼寫」的設定檔。這一層讓 LLM 不會每次亂寫,而是像一個有紀律的 Wiki 維護者。

然後三個操作循環:
- Ingest(攝入):新資料進來時,LLM 閱讀、摘要、更新相關頁面、補充交叉引用
- Query(查詢):問問題時,LLM 先讀 Wiki(不是 raw sources),快速給出答案。關鍵是:好的答案會被 file-back 寫回 Wiki,成為新頁面
- Lint(健檢):LLM 定期掃描整個 Wiki,找出矛盾、過時、孤立、缺失的頁面,主動修正
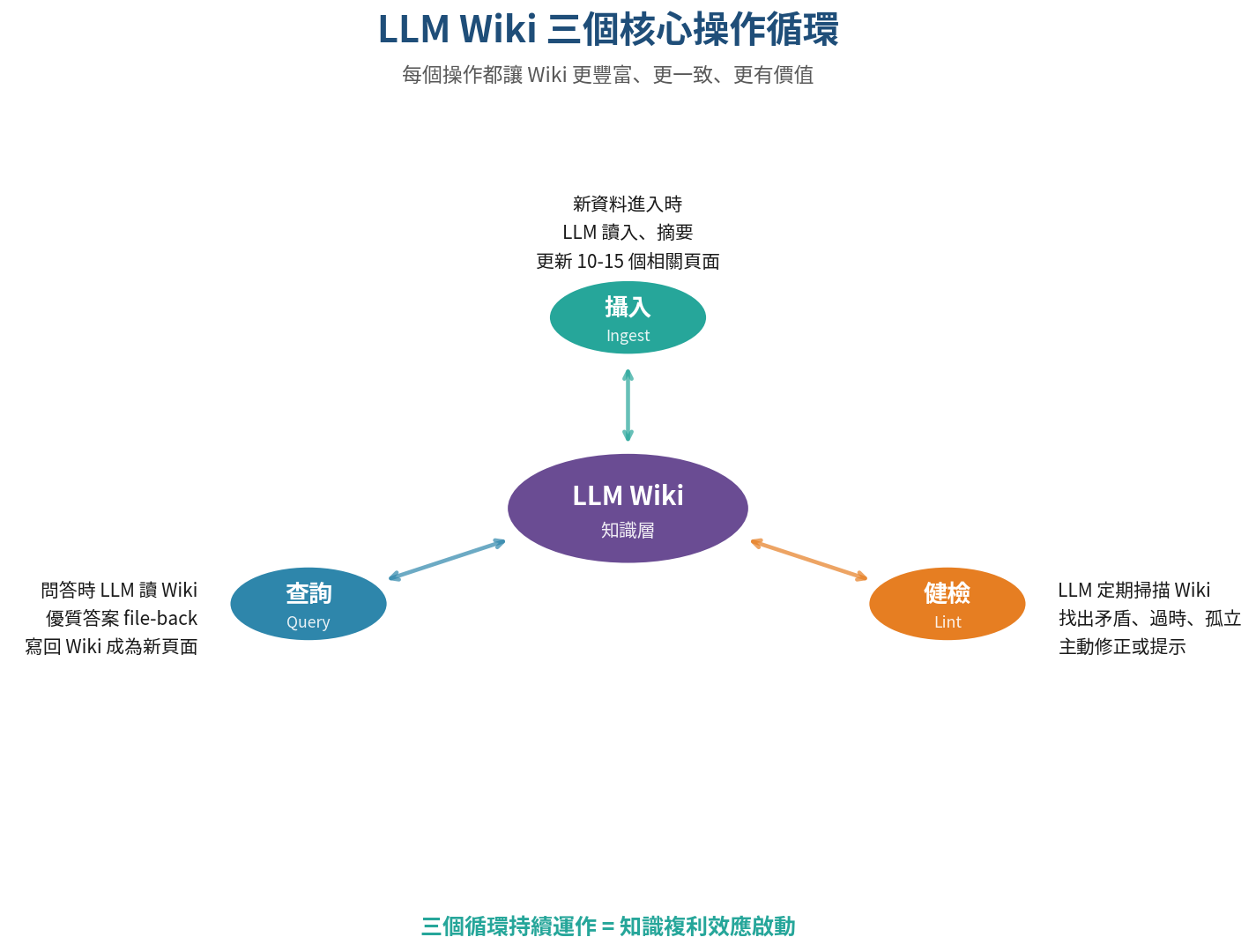
這套架構最迷人的地方是它的累積效應:每一次 ingest 讓 Wiki 更豐富、每一次 query 讓 Wiki 更完整、每一次 lint 讓 Wiki 更一致。用得越多,變得越聰明 — 這就是「知識複利」在技術層面的具體實現。
Karpathy 自己用這個架構做了一個研究用的 Wiki,大約 100 篇文章、40 萬字,規模不大但效果顯著。他在 Gist 最後寫了一句很值得琢磨的話:「這裡面有巨大的產品空間,而不只是一堆臨時腳本的組合。」
這句話,正是百原科技過去一年在做的事。
第三部分:從「想法」到「可用產品」之間,有六個關鍵差距
Karpathy 的 Gist 發表後,GitHub 評論區出現了大量技術圈的批評聲浪,其中最尖銳的幾個點,剛好暴露出「個人研究用的原型」與「企業可用的產品」之間的巨大鴻溝。
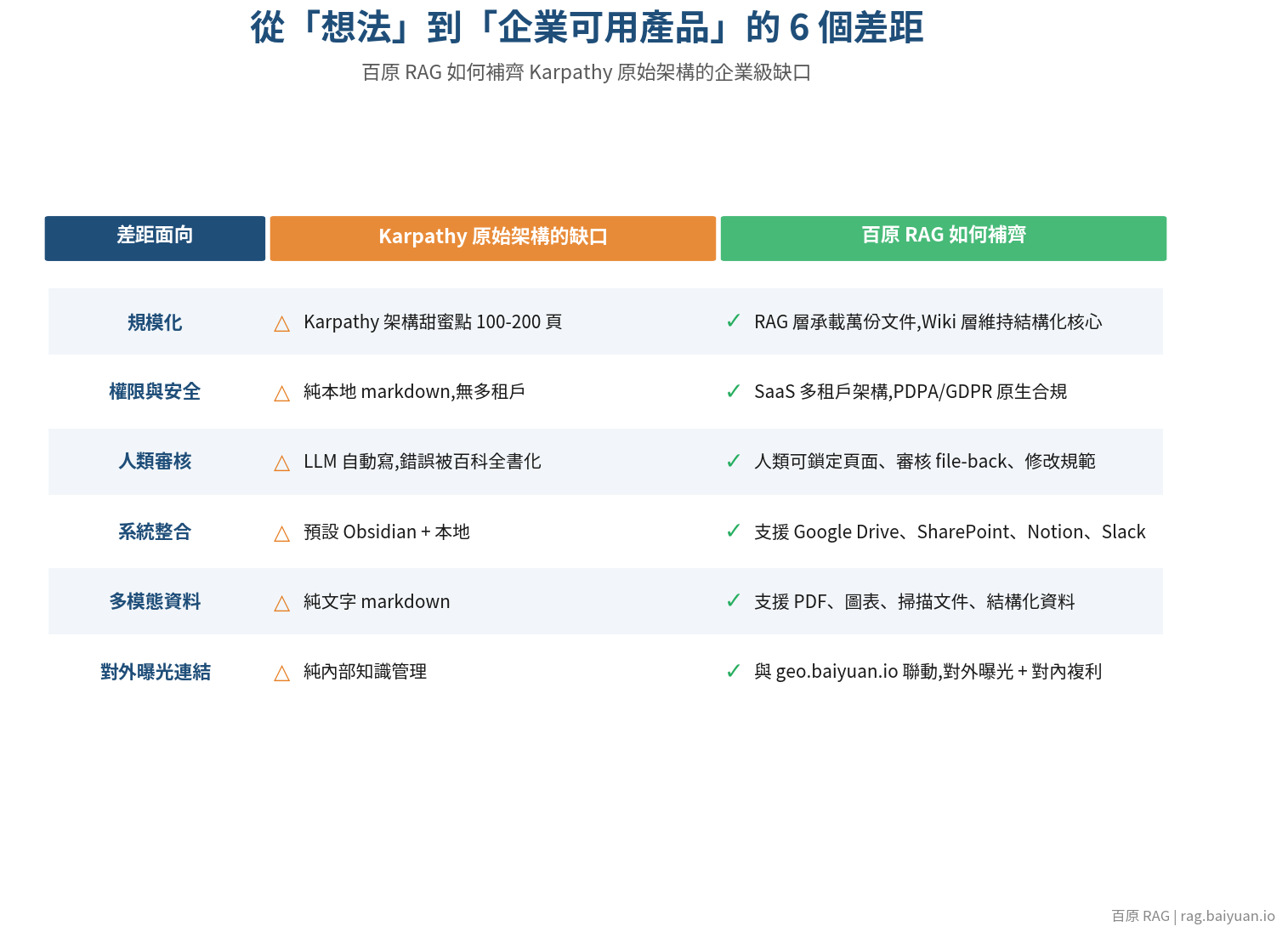
差距一:規模化問題
Karpathy 自己承認他的 Wiki 規模約 100 篇文章。GitHub 評論區也有多位工程師實測後回報,這個架構的「甜蜜點」大約在 100-200 頁,超過後 LLM 掃描 index 的效率會顯著下降。
對一個「個人研究助理」來說這沒問題,對企業來說卻是致命傷。一家中型公司的知識庫輕鬆就超過 10,000 份文件。純 Markdown + 沒有向量資料庫的架構,根本撐不住企業級負載。
差距二:權限與安全
Karpathy 的架構是 git repo + local markdown,適合個人或小團隊。企業場景下需要處理:
- 多部門、多角色的權限隔離(業務部門不該看到 HR 機密文件)
- 多租戶(代理商服務多客戶時,不能讓客戶 A 的資料污染客戶 B)
- 合規需求(PDPA、GDPR、金融業、醫療業各自的法規)
- 稽核軌跡(誰、什麼時候、讀了什麼、改了什麼)
純 Markdown 無法優雅處理這些,必須有完整的後端系統。
差距三:人類審核與可控性
批評者最強的一個論點是:LLM 寫 Wiki 的過程中會產生幻覺,錯誤會被「百科全書化」 — 看起來權威,但是錯的。
Karpathy 自己也承認,他每次 ingest 都要 babysit(盯著看、給指導),並非真正零維護。個人研究可以這樣,企業級應用則必須有明確的人類審核流程、校對機制、版本比對。
差距四:與既有知識系統的整合
企業不會從零開始建知識庫。他們有 SharePoint、Confluence、Notion、Google Workspace、ERP、CRM、客服系統。能不能快速接上這些資料源,而不要求客戶把所有資料搬家?Karpathy 的架構預設是 Obsidian + 本地 markdown,企業環境完全無法套用。
差距五:多模態資料
企業資料不只有文字。規格書有圖表、產品手冊有示意圖、會議錄音有音檔、客戶提供的 PDF 有掃描頁。純 markdown 的 Wiki 處理這些能力有限。
差距六:與 AI 搜尋生態的連結
最關鍵的一點 — LLM Wiki 本身解決了「對內」的知識管理,但企業還需要「對外」的曝光:ChatGPT、Claude、Gemini、Perplexity 被問到你的產業問題時,你的品牌有沒有被引用?這就是 GEO(生成式引擎優化)的戰場,需要跟 LLM Wiki 聯動,形成完整的「知識進、曝光出」閉環。
這六個差距,每一個都不是小工程師幾個週末能補起來的。它需要一個專門的團隊、一整套後端基礎設施、以及對企業場景的深刻理解。這也是為什麼 rag.baiyuan.io 這個產品會存在。
第四部分:rag.baiyuan.io 做了什麼
百原科技在 rag.baiyuan.io 推出的產品,核心 slogan 是「會自己成長學習的知識庫 LLM Wiki」,產品定位是「LLM Wiki + RAG 雙層智慧知識引擎」。
這兩句話背後,其實是把 Karpathy 的想法變成企業可用產品的工程結晶。我們來拆解看看:
設計決策一:LLM Wiki + RAG 雙層,而不是擇一
這是百原最重要的架構決策。
Karpathy 的原始提案,隱隱有「用 LLM Wiki 取代 RAG」的傾向(Gist 開頭就在對比兩者)。但純 LLM Wiki 有規模上限,純 RAG 又沒有複利效應。最優解是雙層並用:
- LLM Wiki 層:處理結構化、概念化、可累積的高品質知識(類似「編輯好的百科全書」)
- RAG 層:處理大規模、即時、細粒度的原始文件檢索(類似「倉庫索引」)

當 AI 被問問題時,先查 Wiki(快速、結構化、已編譯),Wiki 不足的細節才下鑽到 RAG 層撈原始文件。這樣既有 Wiki 的複利累積,又有 RAG 的海量搜索能力。
這也是為什麼百原的產品名稱特別強調「雙層智慧知識引擎」 — 這不是行銷話術,是技術架構上的本質選擇。
設計決策二:SaaS 多租戶,而非個人 markdown repo
Karpathy 的提案是個人 git repo,百原做的是多租戶 SaaS。這個決策解決了前面講的「差距二」 — 權限、租戶隔離、合規稽核全部內建。
這意味著:
- 代理商可以用同一個平台服務多個客戶,資料完全隔離
- 企業內部可以按部門、角色設定不同的 Wiki 可見性
- PDPA、GDPR 合規是平台原生能力,不是事後補丁
- 所有 LLM 對 Wiki 的修改都有版本紀錄,可回溯、可審查
設計決策三:自己成長,但人類可以介入
百原的產品強調「會自己成長學習」,但不強迫自動化。這直接回應前面「差距三」的質疑。
具體來說:
- Ingest 時,LLM 寫 Wiki,但人類可以審核、修改、鎖定(locked)特定頁面
- Query 時,LLM 可以 file-back 優質答案,但由人類決定是否納入 Wiki
- Lint 時,LLM 主動提醒矛盾與過時,但修改需要人類核准
這樣的設計既保留了「複利累積」的本質,又避免了「LLM 幻覺百科全書化」的風險。
設計決策四:與企業既有系統整合
純 Obsidian 本地 markdown 在企業場景用不動,rag.baiyuan.io 的產品定位是「企業 AI 知識管理平台」,從第一天就設計成可以對接企業既有資料源的 SaaS。
設計決策五:與 geo.baiyuan.io 形成完整生態
這是百原最獨特的戰略位置。
市面上做 RAG 的不少,做 GEO 的也不少,但同時擁有對內知識引擎(RAG Wiki)和對外曝光引擎(GEO Platform)的完整生態,目前極少。
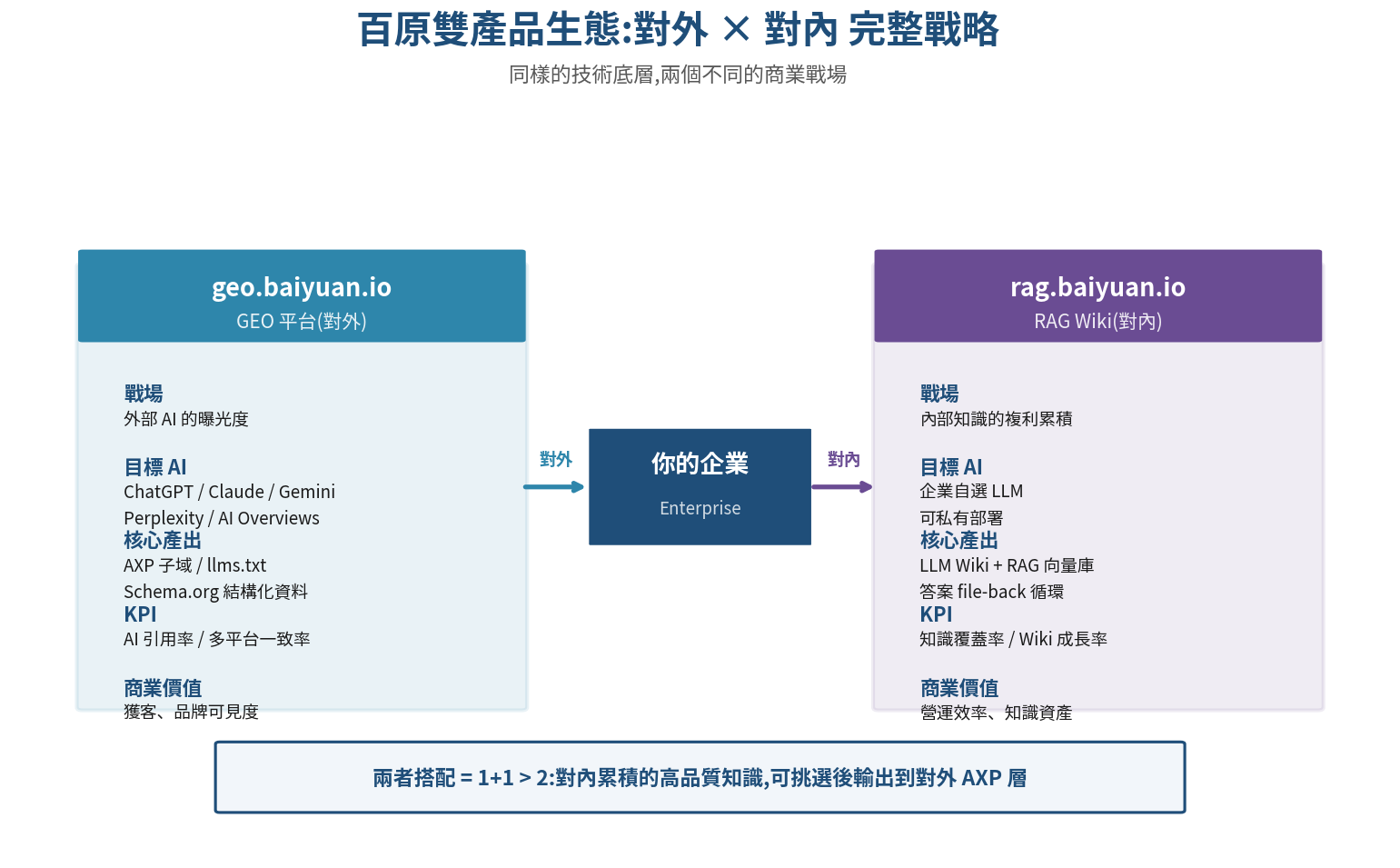
兩個產品的分工與互補關係是這樣的:
| 層面 | geo.baiyuan.io(GEO 平台) | rag.baiyuan.io(RAG Wiki) |
|---|---|---|
| 主要戰場 | 品牌在外部 AI 的曝光度 | 企業內部的知識複利 |
| 目標 AI | ChatGPT、Claude、Gemini、Perplexity、AI Overviews | 企業自己選擇的 LLM(可私有部署) |
| 核心產出 | AXP 子域、llms.txt、Schema.org 結構化資料 | LLM Wiki、RAG 向量庫、答案 file-back |
| 測量指標 | AI 引用率、多平台一致率 | 知識覆蓋率、問答滿意度、Wiki 成長率 |
| 商業價值 | 獲客、品牌可見度 | 內部效率、知識資產 |
同一家企業可以同時使用兩個產品,也可以只選一個。但對有野心的企業來說,兩個搭配使用會產生 1+1 > 2 的綜效 — 對內累積的高品質知識(RAG Wiki),可以被挑選、結構化後輸出到對外的 AXP 層(GEO),讓 AI 引用的內容質量大幅提升。
第五部分:對 CEO/行銷長,這在商業上意味著什麼
技術講完了,回到商業語言。你的企業為什麼應該現在就把 LLM Wiki + RAG 雙層架構納入 2026 年的 AI 投資規劃?
理由一:知識資產的折舊正在加速
AI 進入企業越深,「一次性答案」的浪費就越明顯。每一次員工用 AI 問問題、每一次客戶對話被 AI 摘要、每一次會議被 AI 總結 — 如果這些價值沒有被「捕捉、編譯、累積」進一個持續成長的知識庫,它們都會隨著對話視窗關閉而蒸發。
你現在不決定,知識資產的折舊速度只會越來越快。
理由二:時機視窗正好
LLM Wiki 這個架構理論,是 2026 年 4 月才被業界正式提出;百原的雙層引擎產品,正好在這個時機點成熟上線。
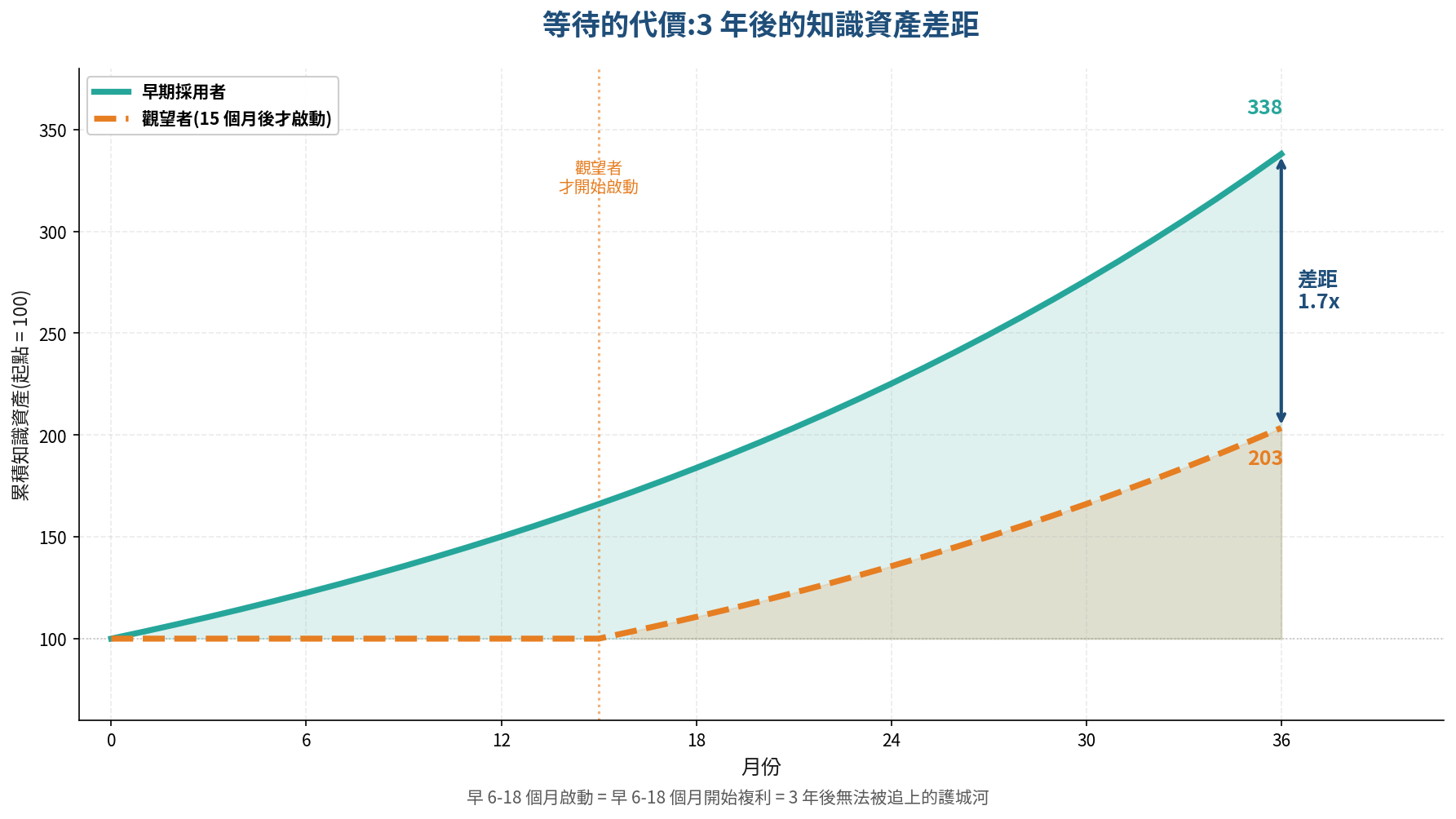
這意味著台灣企業現在有一個非常罕見的視窗 — 在一個剛形成的技術典範上,不必等歐美市場驗證完再追,可以直接採用一個本土就已經把它工程化、產品化、SaaS 化的方案。這個視窗在過去十年的技術潮流裡(雲端、容器、機器學習),台灣企業普遍都晚了 2-3 年才跟上。這次不同。
理由三:採用成本與轉換成本呈反比
越早採用 LLM Wiki 架構,越早開始累積 Wiki 資產,複利效應就越早啟動。
三年後的情況會是這樣:
- 早期採用者:Wiki 已累積 3 年、數千個結構化知識頁面、跨部門連結已成熟、AI 對公司脈絡的理解深度遠超通用模型。要轉換到其他平台,轉換成本極高(因為資產龐大),但平台鎖定同時也是競爭對手極難追趕的護城河。
- 觀望者:三年後才開始建置,面對一個已經被競爭對手用 3 年時間拉開差距的知識複利曲線。就算買同樣的產品,也買不回失去的三年。
理由四:與 GEO 雙軌是完整戰略
前面提過,對外用 GEO、對內用 RAG Wiki,是 2026-2028 年企業 AI 戰略的完整架構。
對外 GEO 讓你被 AI 看見、被 AI 推薦、被 AI 引用 — 影響的是獲客效率。
對內 RAG Wiki 讓你的員工用 AI 時真正用到公司脈絡、讓每次 AI 互動累積成知識複利 — 影響的是營運效率。
兩者都做,是戰略完整性。只做一個,會有明顯的戰略缺口。
第六部分:常見誤解與釐清
誤解一:「這不就是更貴的 Notion AI 或 Confluence + AI 嗎?」
不是。Notion AI 或 Confluence 的 AI 功能,本質是「在既有頁面上提供 AI 輔助寫作」 — 人寫、AI 幫潤飾。
LLM Wiki 的核心是「LLM 寫、人類審核」 — 角色完全相反。它不是替既有 Wiki 加 AI 功能,而是讓 AI 成為 Wiki 的主要維護者,人類從「每天寫文件」變成「策展、提問、監督」。
這是兩種完全不同的產品邏輯。
誤解二:「我們公司 AI 用量不大,不需要」
這個誤解來自把 LLM Wiki 當成「AI 額外工具」。實際上,它是「AI 投資的倍增器」。
假設你公司 AI 用量真的很小,每月只花一萬元在 AI 工具上。但這一萬元的價值是「用完即丟」還是「累積成資產」,差別會隨著時間呈指數擴大。真正的問題不是用量大小,而是 你有沒有讓每一塊錢的 AI 投入產生複利。
誤解三:「等 ChatGPT 自己進化出這功能就好了」
ChatGPT、Claude、Gemini 各自的「記憶」功能,未來一定會強化。但它們有幾個無法跨越的限制:
- 你的資料會變成 OpenAI/Anthropic/Google 的資產,而不是你的企業資產
- 無法多租戶隔離 — 你的員工 A 和員工 B 使用同一個 ChatGPT 企業帳戶,他們接觸的知識是否該有不同權限?
- 無法深度整合你的系統 — 你的 ERP、CRM、內部資料庫如何對接?
- 無法法規合規 — 資料流向、儲存位置、刪除義務都受制於外商平台
一個獨立的、企業擁有的、可私有部署的 RAG Wiki,是戰略主權問題,不是工具選擇問題。
誤解四:「我們沒有 AI 工程師,做不了」
這正是百原做 SaaS 的理由。rag.baiyuan.io 的產品設計上,不要求客戶有 AI 工程師團隊。
- 後端架構(向量資料庫、LLM 整合、RAG 管線)是平台內建
- Wiki 結構設計由平台預設模板提供,企業只需微調
- 人類審核介面設計得讓一般內容/法遵/營運人員也能操作
- 資料接入支援常見企業系統(Google Drive、SharePoint、Notion、Slack 等)
企業要做的,是「決定哪些知識要進來、誰可以看、如何使用」— 這些是業務決策,不是技術實作。
第七部分:怎麼開始?
如果你看到這裡,覺得這件事值得啟動,建議以下三步驟:
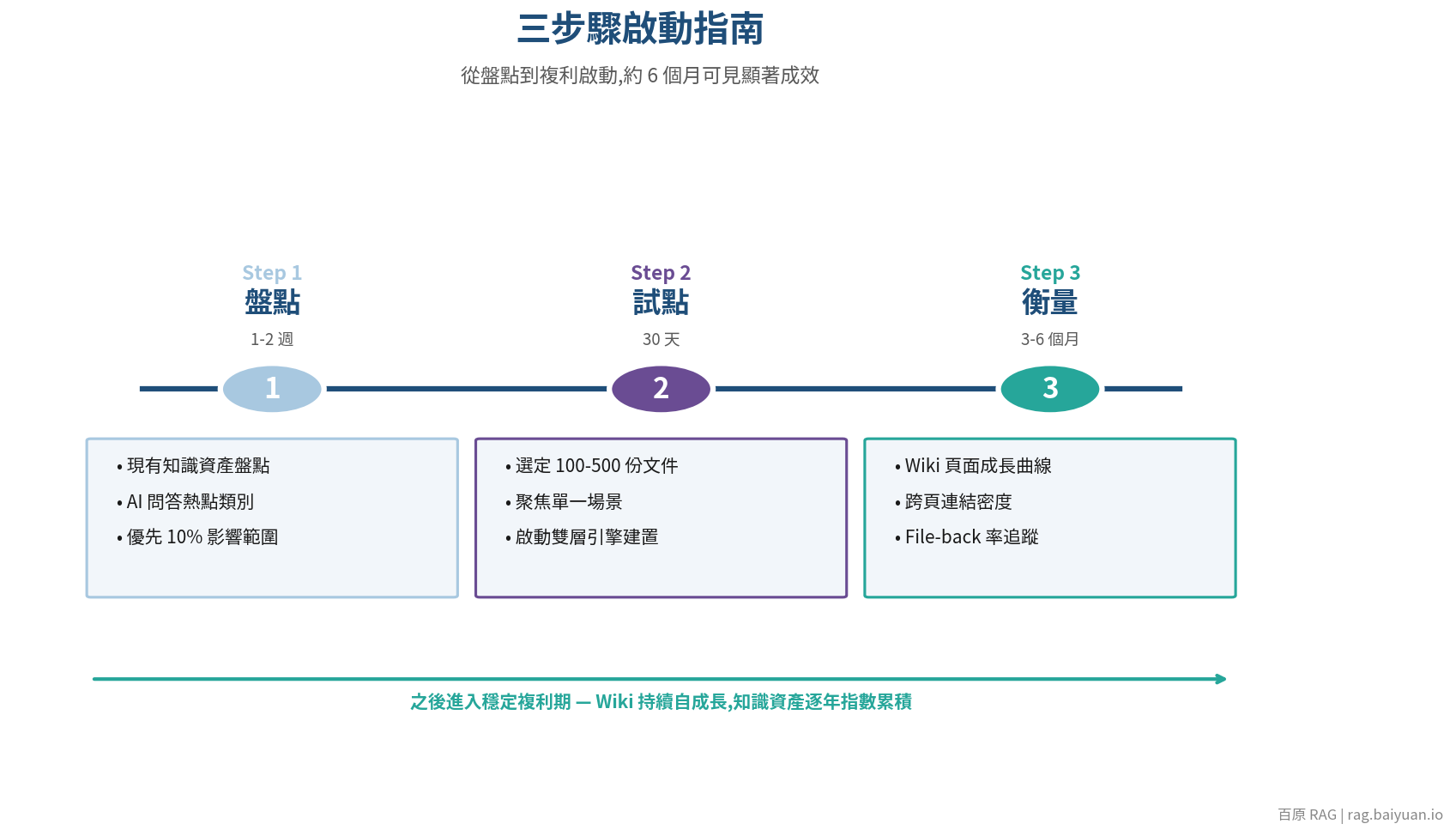
步驟一:盤點現有知識資產(1-2 週)
不需要找 AI 顧問,先內部做一次簡單盤點:
- 公司過去 3-5 年累積的關鍵文件大概有多少?分散在哪些系統?
- 員工平常需要問 AI 的問題,主要集中在哪些類別(產品、法遵、流程、技術)?
- 哪 10% 的內部知識,如果被結構化、可被 AI 隨時引用,會對營運效率產生最大影響?
這個盤點不需要完美,只需要讓你對「啟動後前 90 天要處理什麼」有初步輪廓。
步驟二:試點範圍(30 天)
不要一開始就想把整個公司的知識搬進 LLM Wiki。建議選一個明確有痛點、範圍有限、容易看到成效的試點:
- 某條產品線的所有規格、FAQ、客戶常見問題(幫業務與客服用)
- 某個高複雜度的內部流程(像是跨國稅務、特定產業合規)
- 某個新入職員工培訓常需要的知識庫
試點範圍建議落在 100-500 份文件之間。這個規模足夠驗證成效,又不會因為資料量太大而拖慢啟動速度。
步驟三:衡量複利曲線(3-6 個月)
啟動後的關鍵是看得到複利效應。建議追蹤幾個指標:
- Wiki 頁面數量增長曲線(不是越多越好,而是看成長速度與成熟度)
- 跨頁面連結密度(代表知識網絡的豐富度)
- 員工 AI 問答的答案準確率與滿意度(對照試點前基線)
- File-back 率(多少優質 AI 問答被寫回 Wiki 成為新資產)
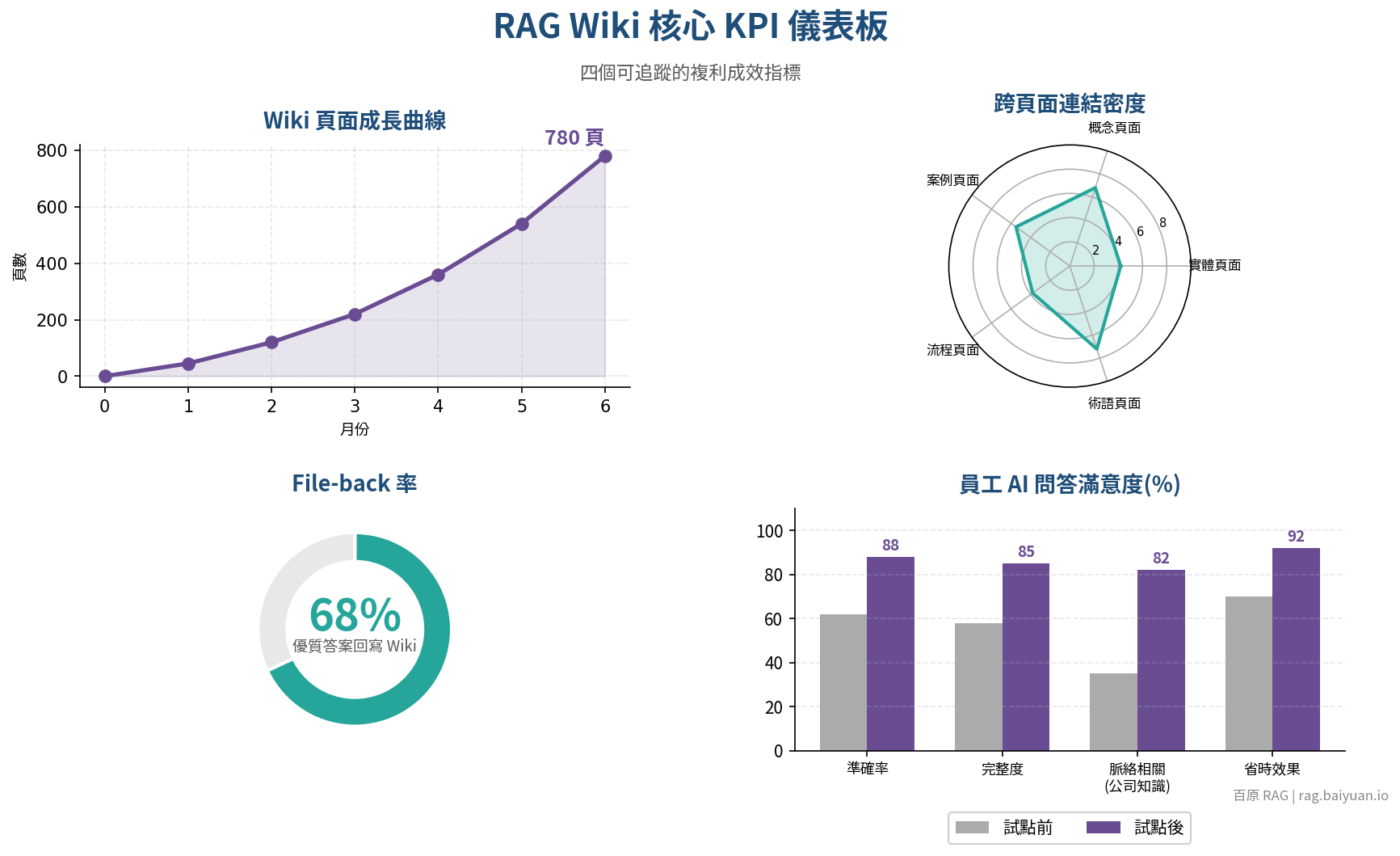
如果 3-6 個月後,這些指標呈穩定向上曲線,恭喜你 — 你的 AI 投資已經從折舊模式切換到複利模式了。
結語:一個時代的轉折點
過去 30 年,企業累積知識的方式有幾次典範轉移:紙本檔案 → 本機電腦 → 網路磁碟 → 雲端文件 → SaaS 知識庫。
每一次轉移,先動手的企業都享有接下來 5-10 年的營運效率優勢。現在 LLM Wiki + RAG 雙層架構,可能是下一次這樣級別的轉移 — 而且這次的複利效應,會比過去任何一次都還要顯著,因為知識本身會「主動成長」,而不是等著被人寫。
Karpathy 提出概念、百原把它工程化成可用的 SaaS。企業要做的決定,只剩一個:你希望 2029 年的自己,是過去三年讓知識資產在複利成長,還是在折舊?
如果答案是前者,我們建議你現在就開始盤點、試點、衡量。這條路需要時間,早啟動 6 個月,三年後的差距會很明顯。
- 了解百原 RAG 平台:rag.baiyuan.io
- 了解百原 GEO 平台:geo.baiyuan.io
- 預約專業諮詢:透過 baiyuan.io 聯絡我們
本文由百原科技有限公司(Baiyuan Technology Co., Ltd.)技術團隊撰寫。百原科技提供企業 AI 時代的完整解決方案,包含對外的生成式引擎優化(GEO)與對內的知識複利引擎(RAG Wiki),協助企業在 AI 典範轉移中建立可持續的競爭優勢。
本文發表於 2026 年 4 月,Karpathy 原始 LLM Wiki Gist 發表於 2026 年 4 月 4 日。